LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “The ‘strong’ feature hypothesis could be wrong” by lsgos
Aug 7, 2024
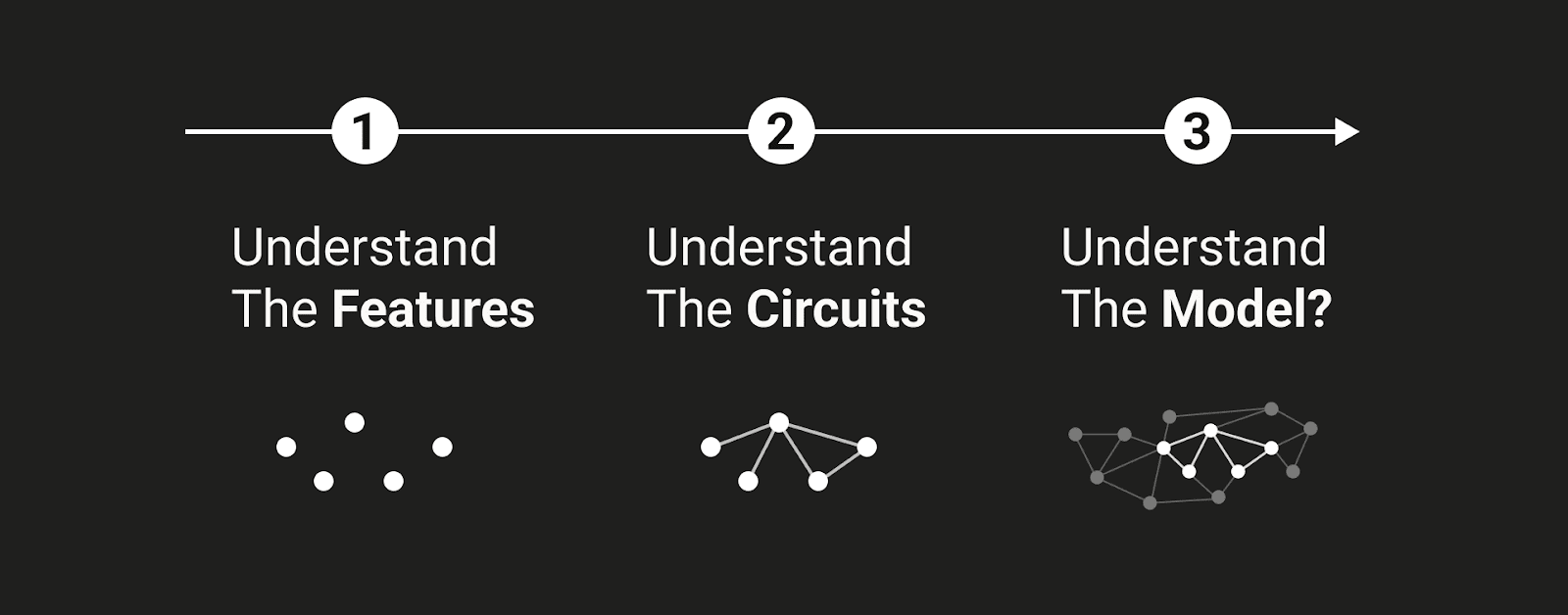
Elhage, a member of the Google DeepMind language model interpretability team, dives deep into the complexities of AI interpretability. They challenge the strong feature hypothesis, arguing that neurons may not correspond to specific visual features as previously thought. The discussants explore the intricate dynamics of explicit versus tacit representations, using chess as a metaphor for decision-making. Elhage also calls for a reevaluation of how we interpret neural networks, advocating for methods that account for context-dependent features.
Chapters
Transcript
Episode notes
1 2 3 4 5
Intro
00:00 • 14min
Navigating the Complexities of Model Interpretability in Machine Learning
13:42 • 2min
Rethinking Interpretability in Computational Models
15:56 • 4min
Exploring Explicit and Tacit Representations in Decision-Making
20:25 • 2min
Understanding Internal Representations and Interpretability in Neural Networks
22:31 • 8min