EA Forum Podcast (Curated & popular)
EA Forum Podcast (Curated & popular) “How Well Does RL Scale?” by Toby_Ord
11 snips
Nov 3, 2025 
Toby Ord, a philosopher focused on global catastrophic risks and AI safety, delves into the scaling of reinforcement learning (RL) in his insightful analysis. He reveals that while RL facilitates longer thought processes for language models, its efficiency is limited compared to inference scaling. Deployment costs rise sharply with increased inference tokens, and achieving performance gains through RL demands astronomical compute increases. Ord discusses the governance implications of these findings, suggesting a shift in AI progress strategies.
AI Snips
Chapters
Transcript
Episode notes
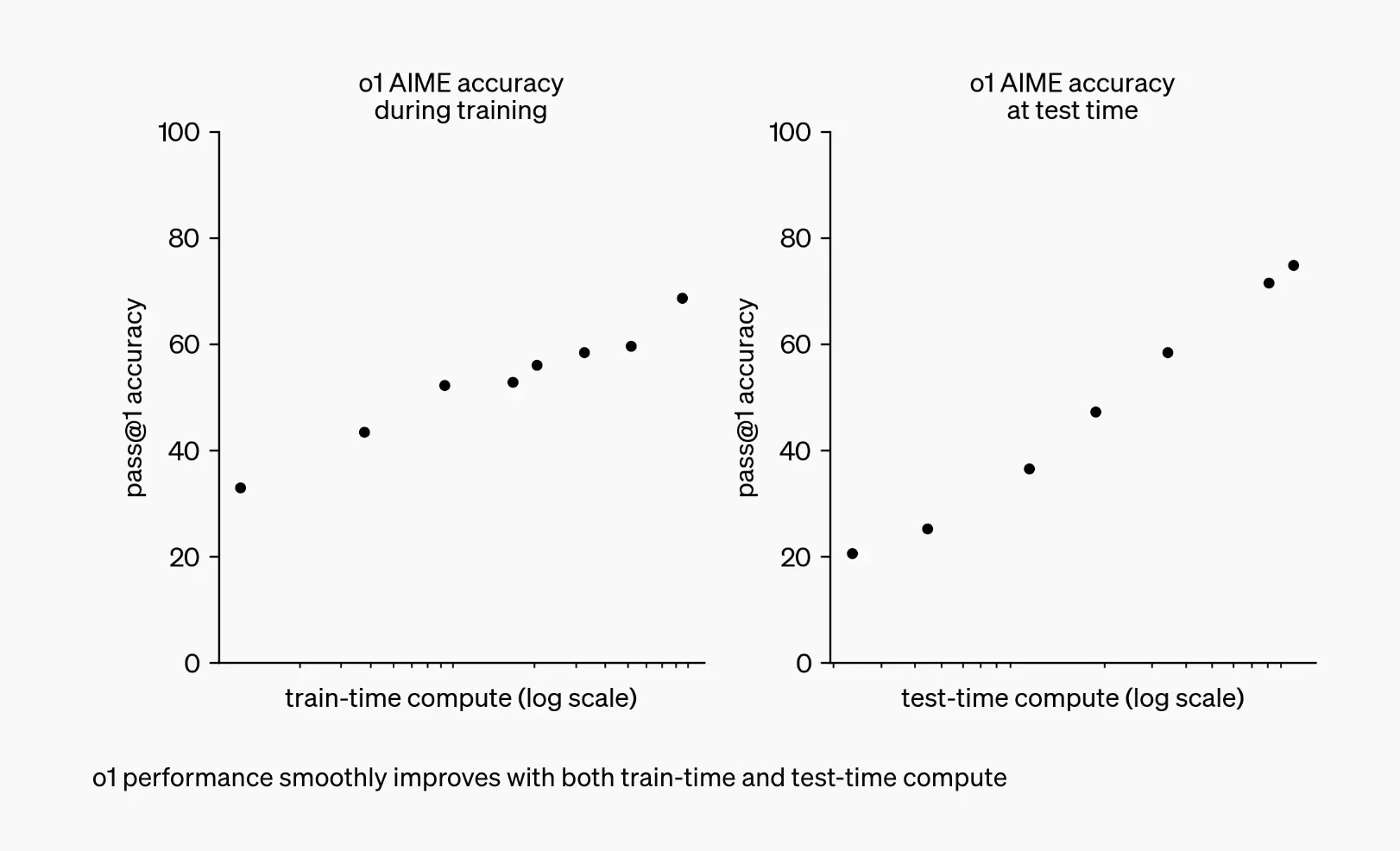
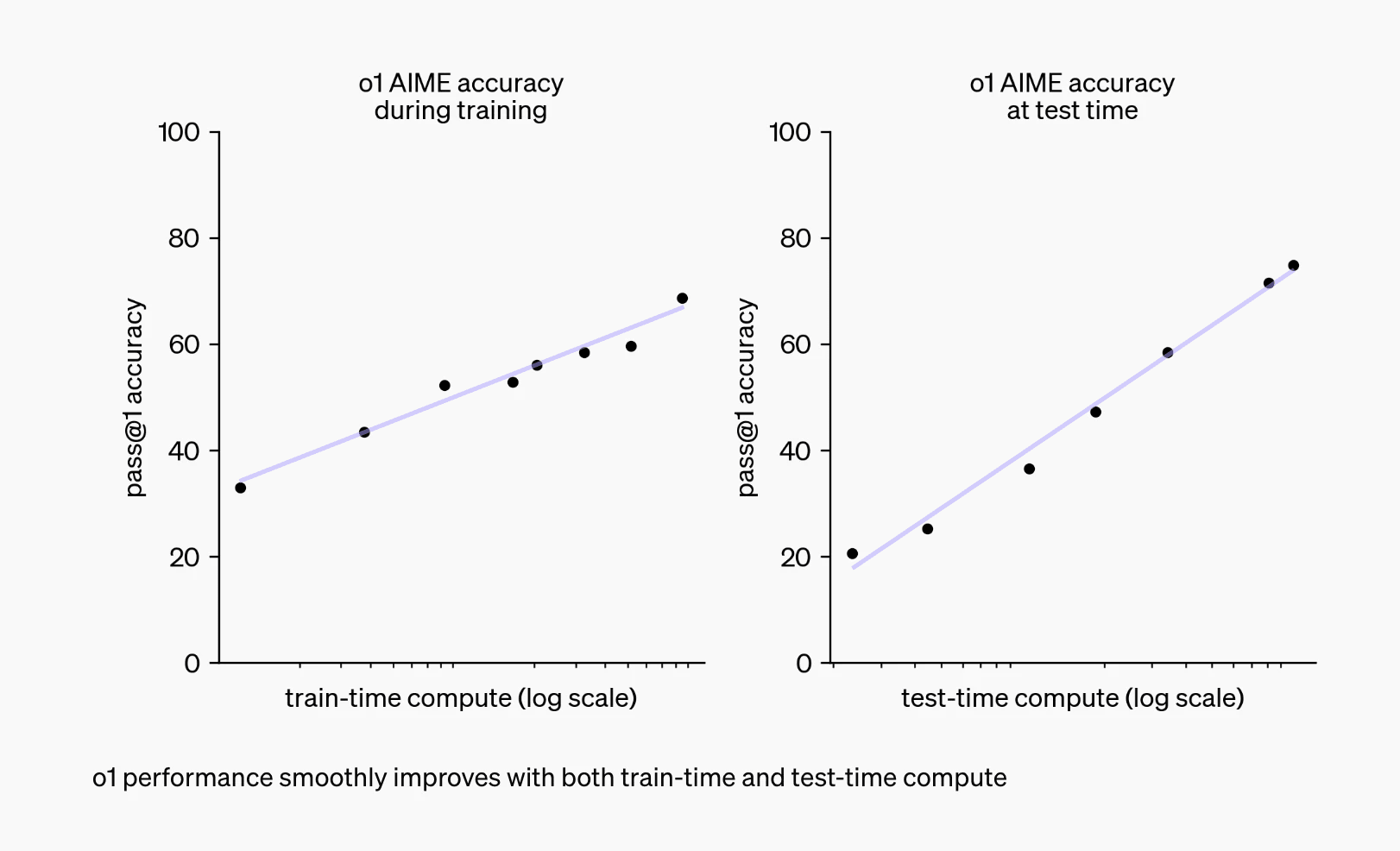
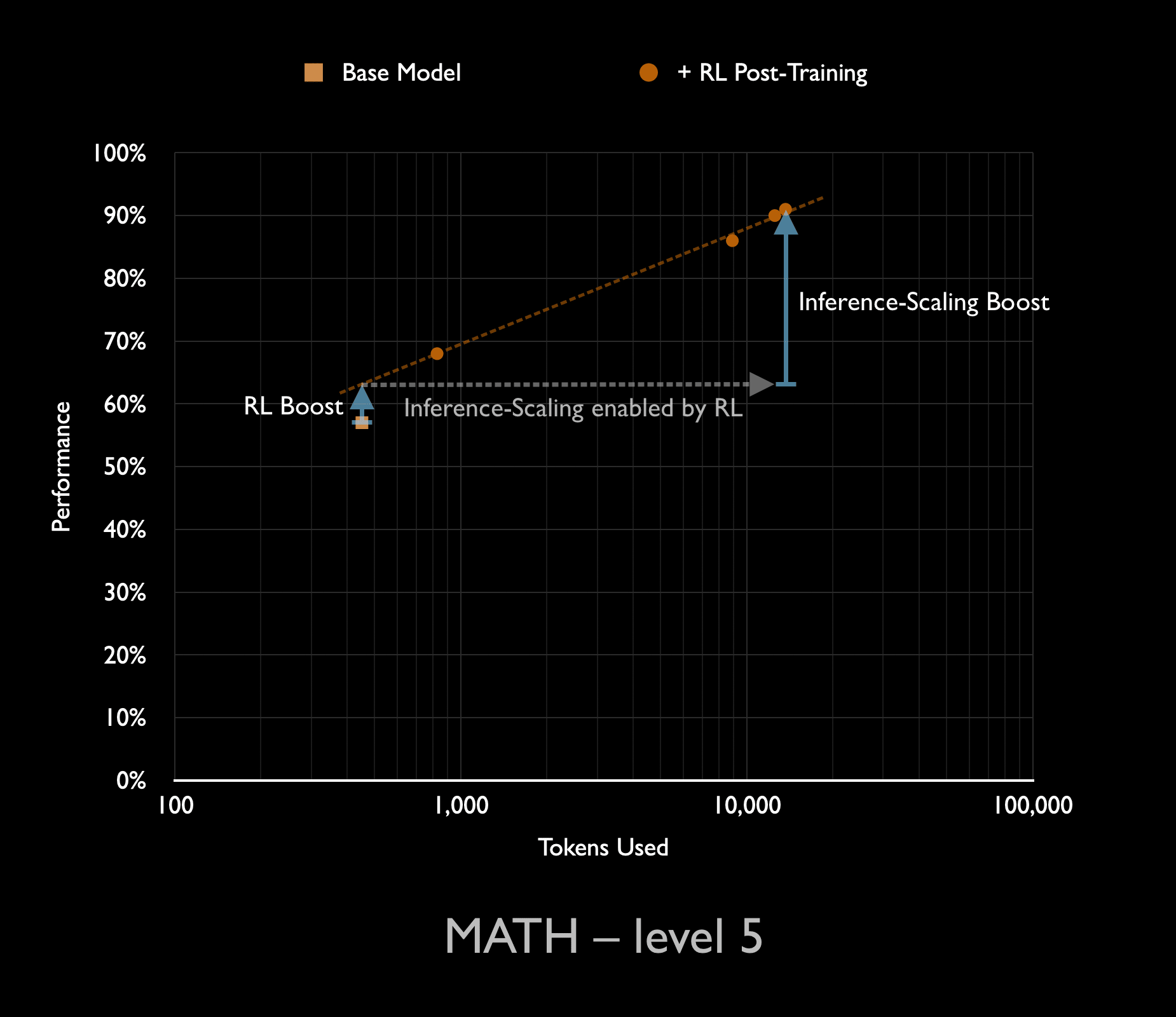
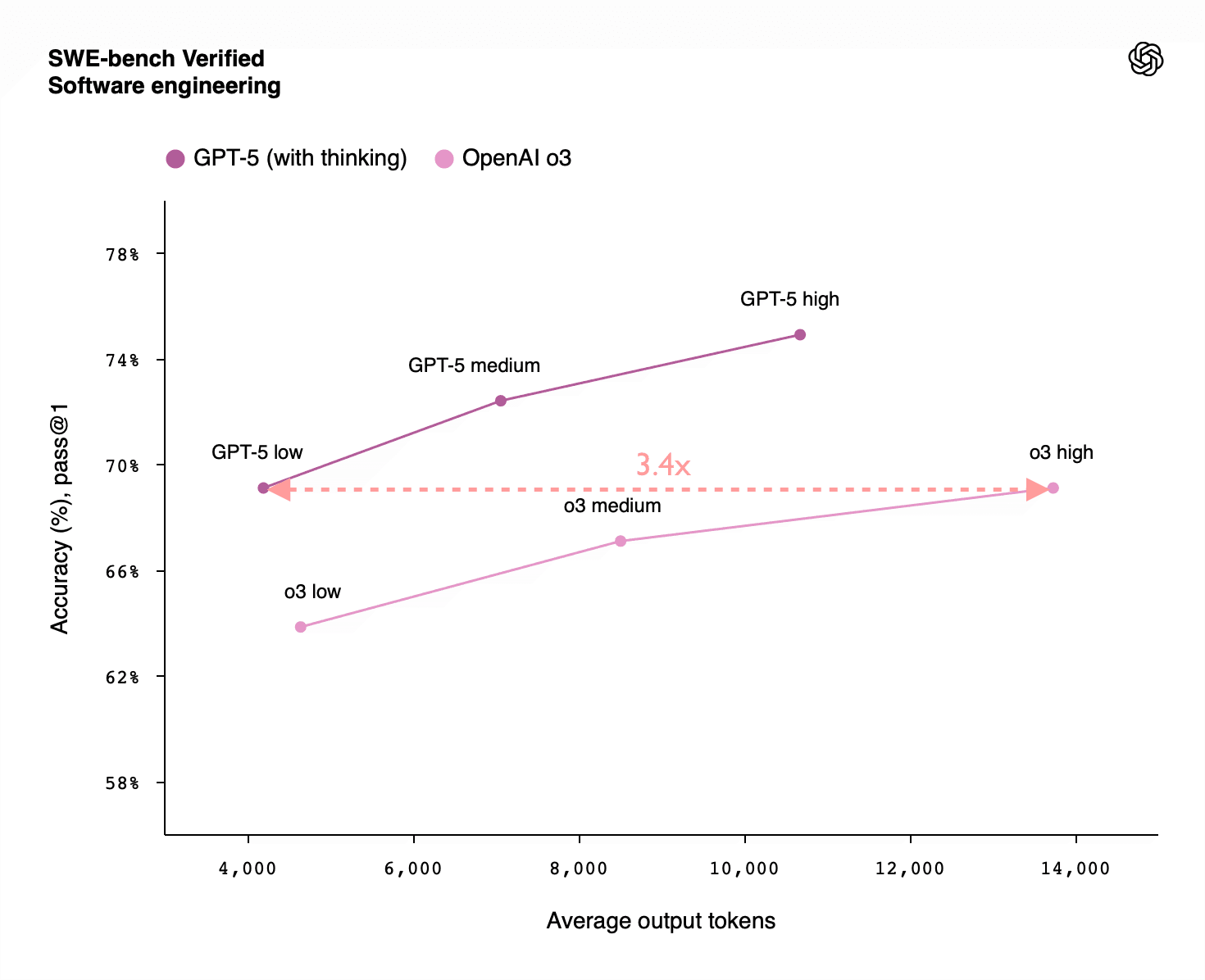
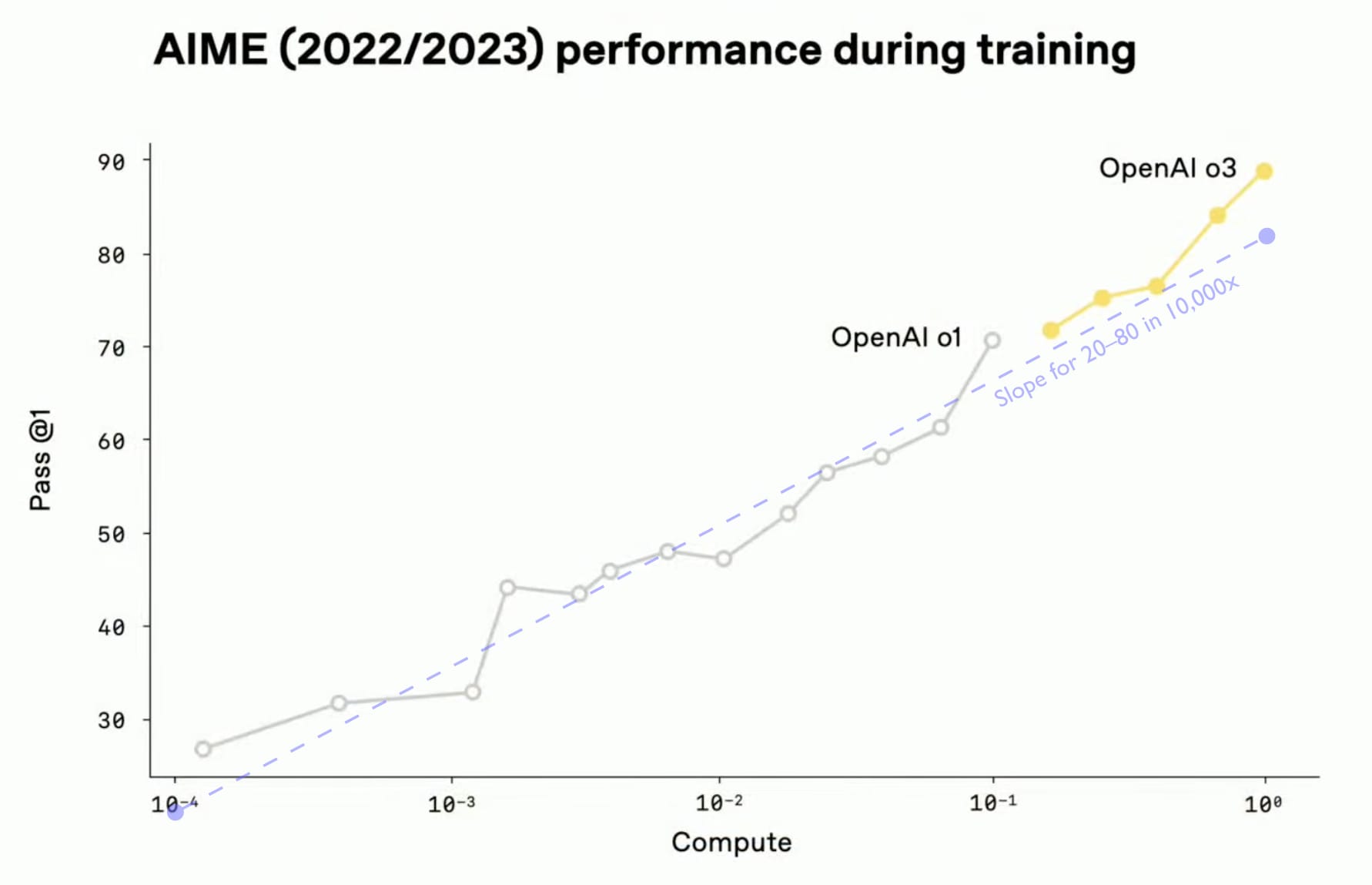
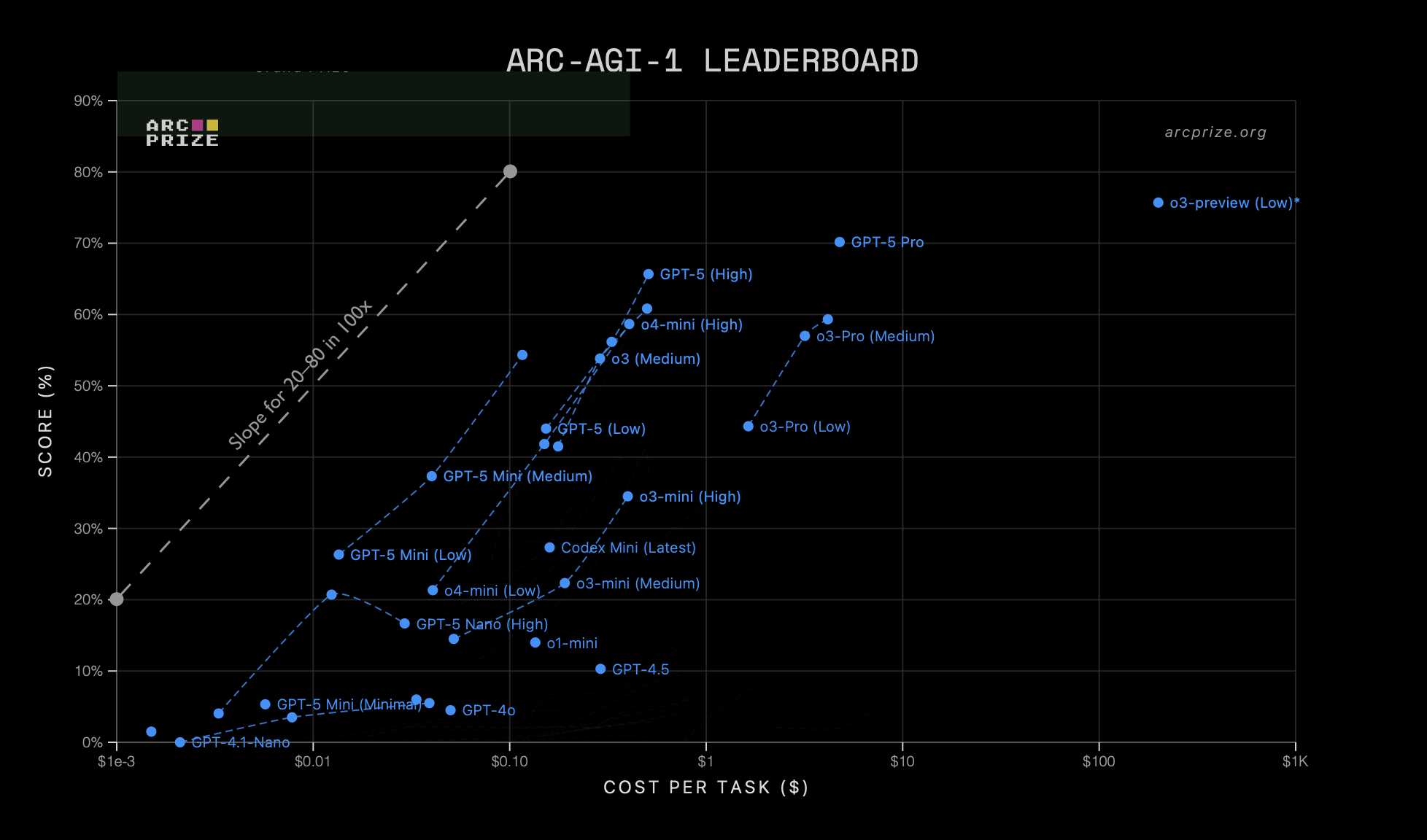
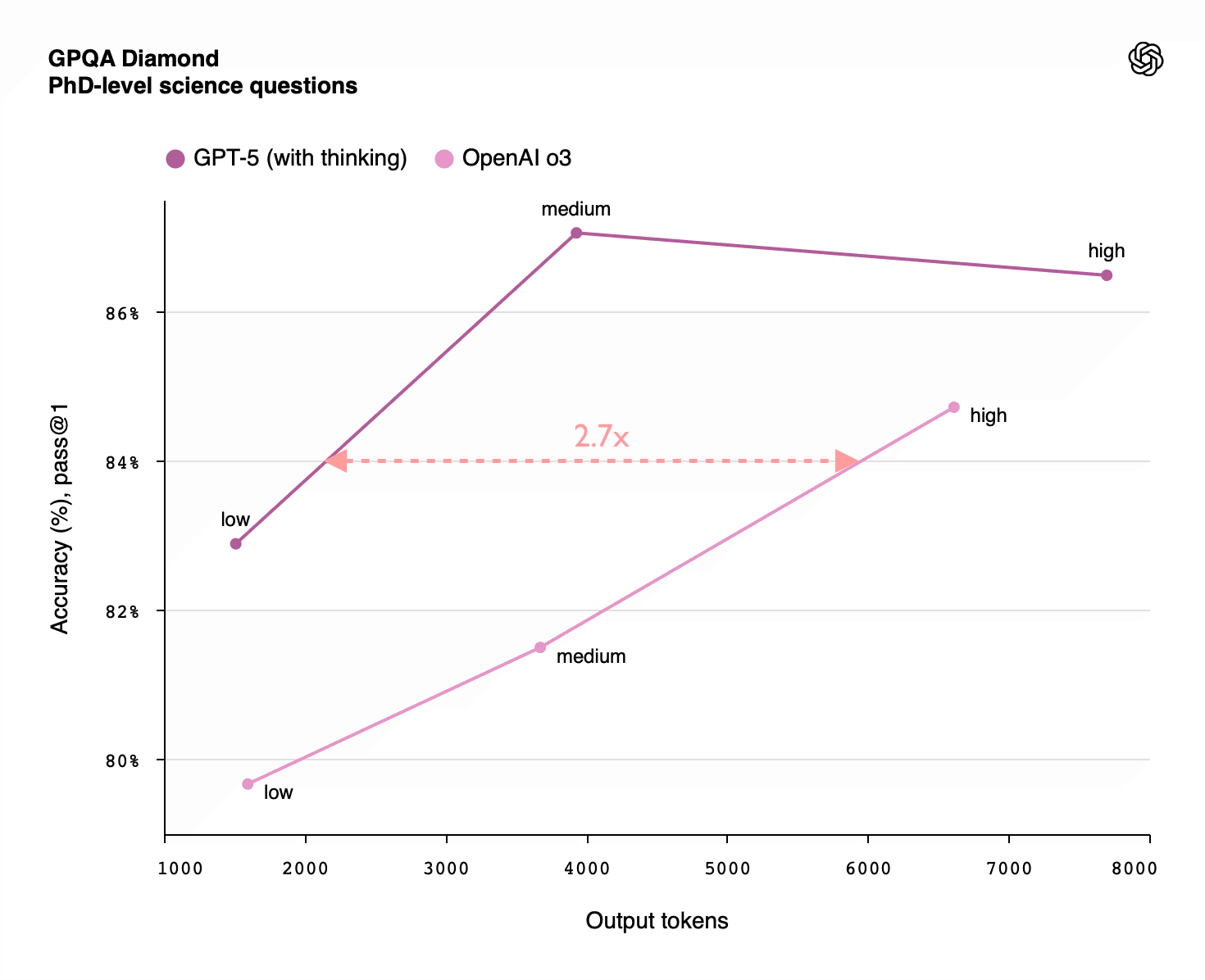
RL Mainly Unlocks Longer Reasoning
- Reinforcement learning (RL) for LLMs produces most gains by enabling much longer chains of thought.
- These inference-length gains matter more than the modest intelligence boost at fixed answer length.
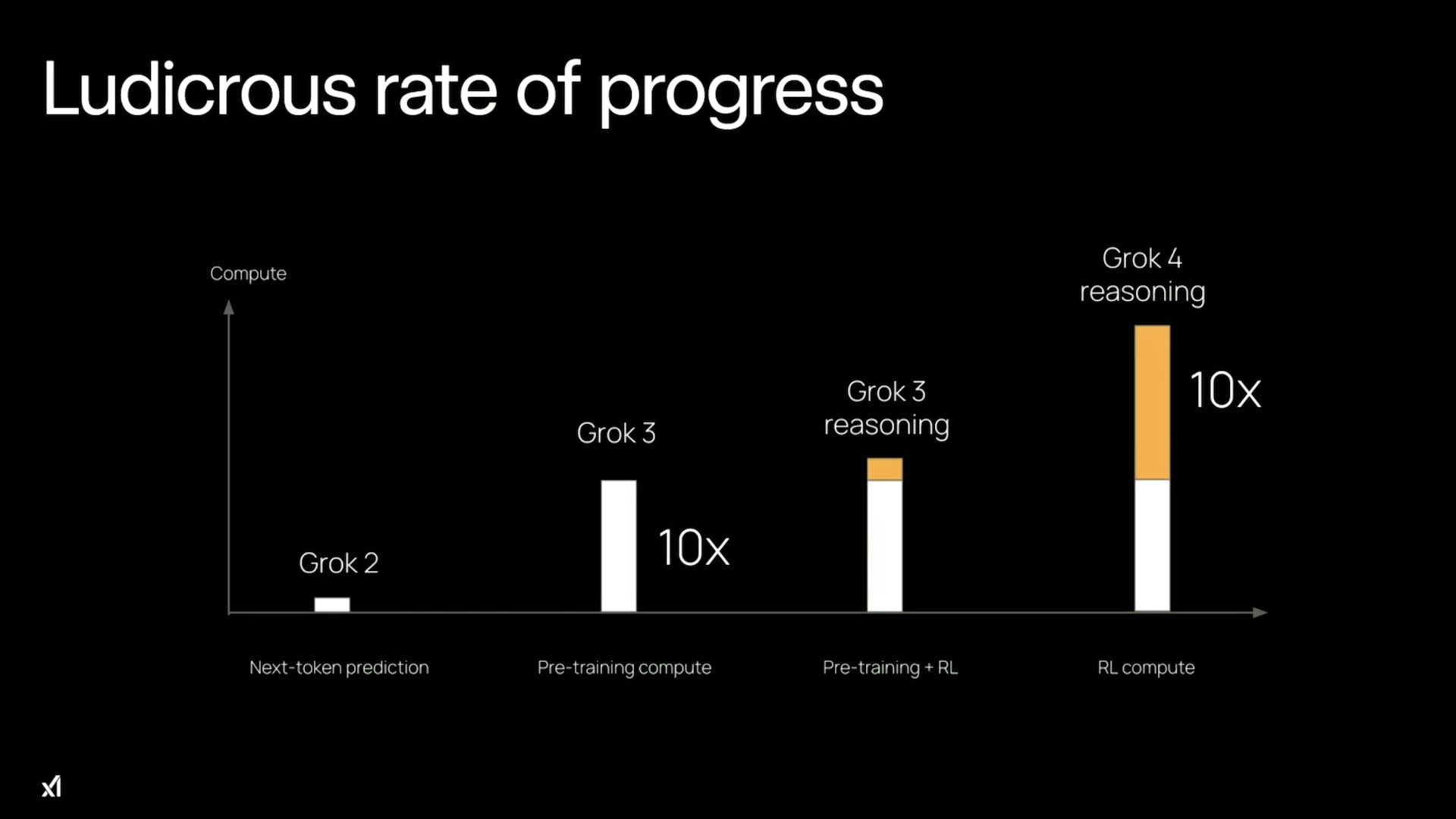
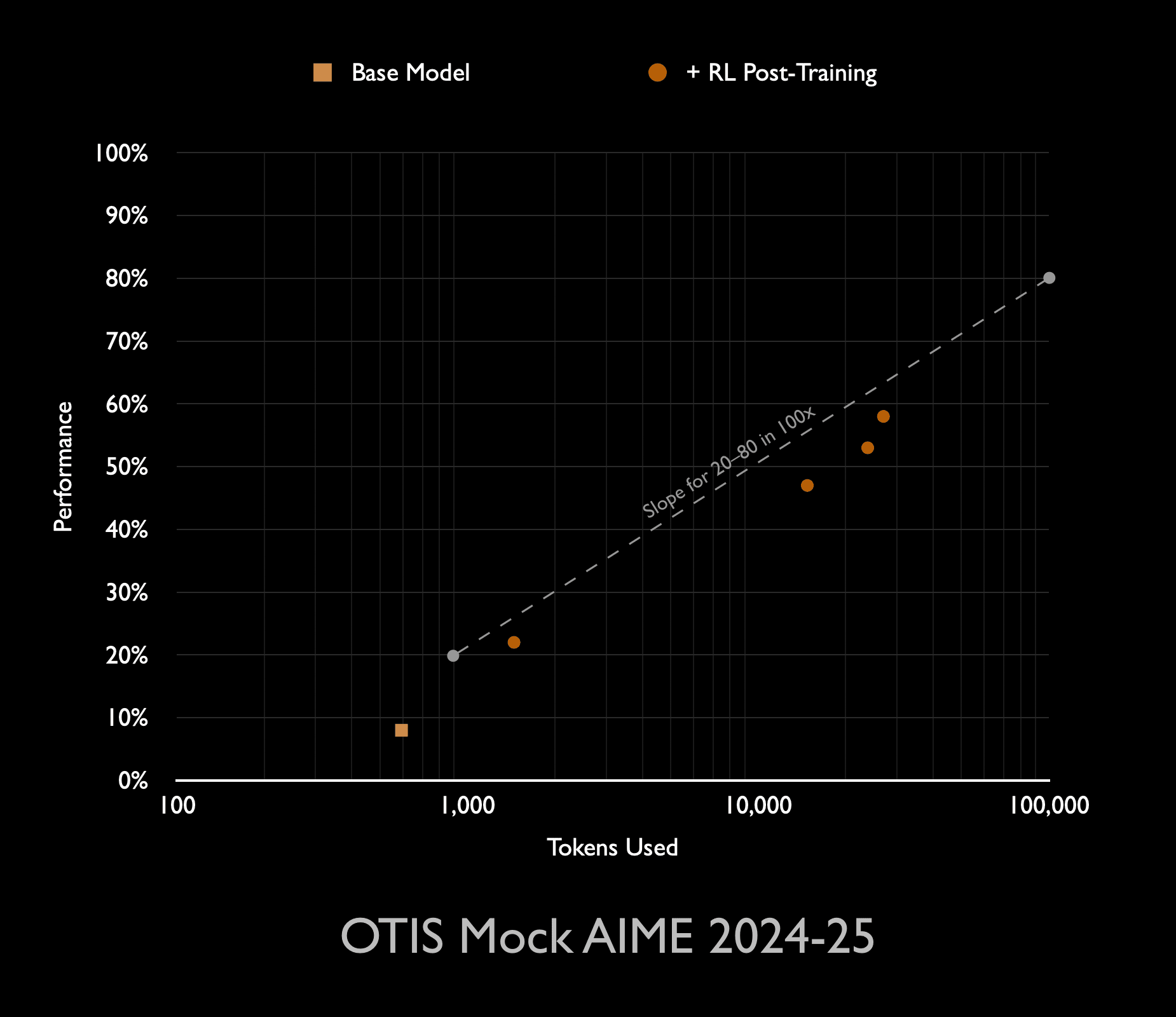
Two Distinct Forms Of Compute Scaling
- I distinguish two compute scalings: RL training compute and inference compute for deployment.
- RL training improves reasoning technique while inference scaling lets the model think longer on each problem.
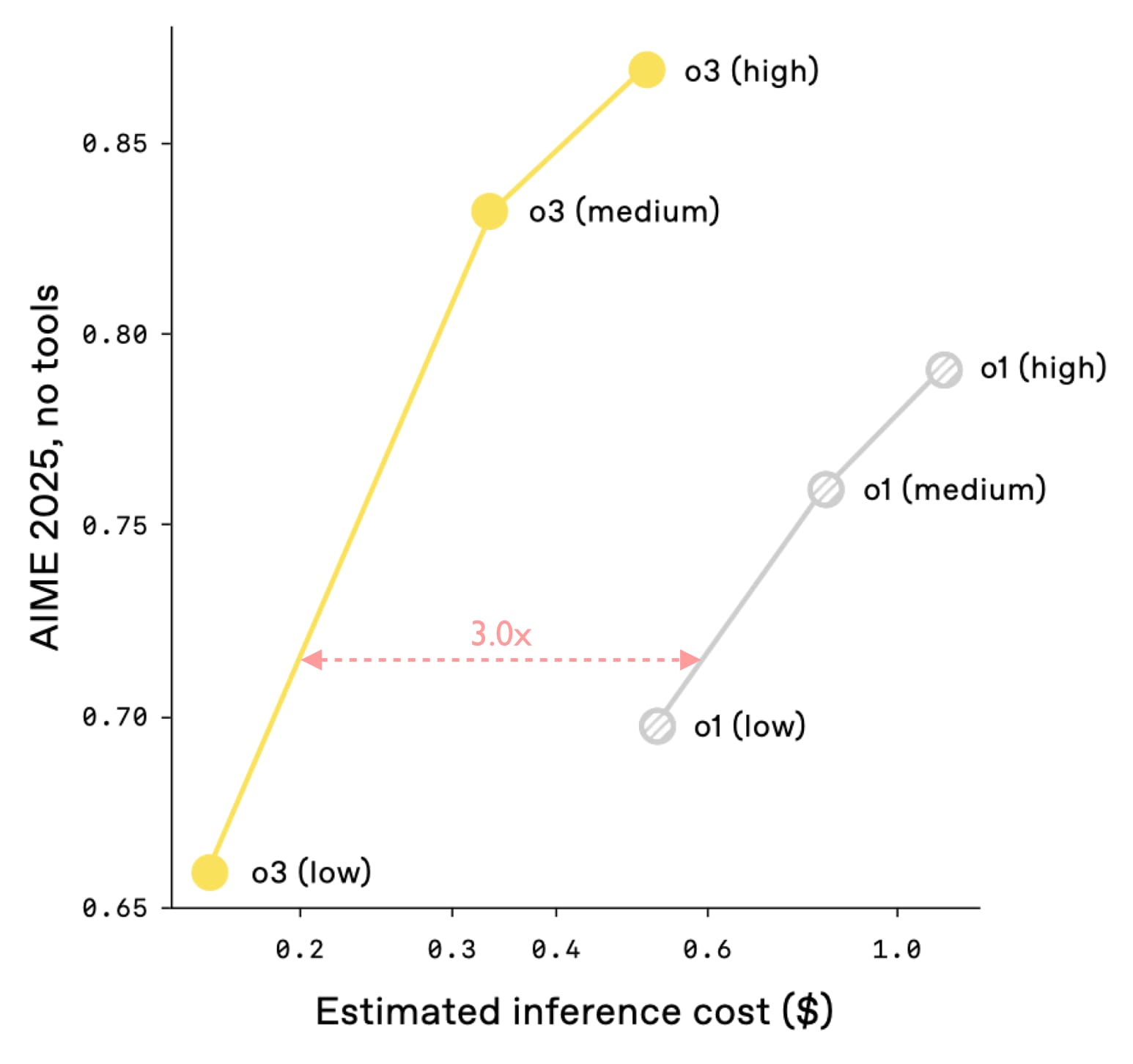
Plan For Higher Deployment Costs
- Expect deployment costs to rise when reasoning uses much longer chains of thought.
- Factor increased per-use inference costs into AI governance and safety planning.