LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “How Well Does RL Scale?” by Toby_Ord
Oct 30, 2025

Toby Ord, a philosopher renowned for his work on global catastrophic risks and AI, delves into how reinforcement learning (RL) scales poorly for large language models (LLMs). He shares insights on the distinction between RL training and inference scaling, highlighting that inference provides more significant gains. Toby discusses the increased deployment costs tied to longer inference chains and warns that as RL compute approaches pre-training scales, it may become economically unfeasible, shifting future AI advancements towards extended inference periods.
AI Snips
Chapters
Transcript
Episode notes
RL Scaling Is Much Less Efficient
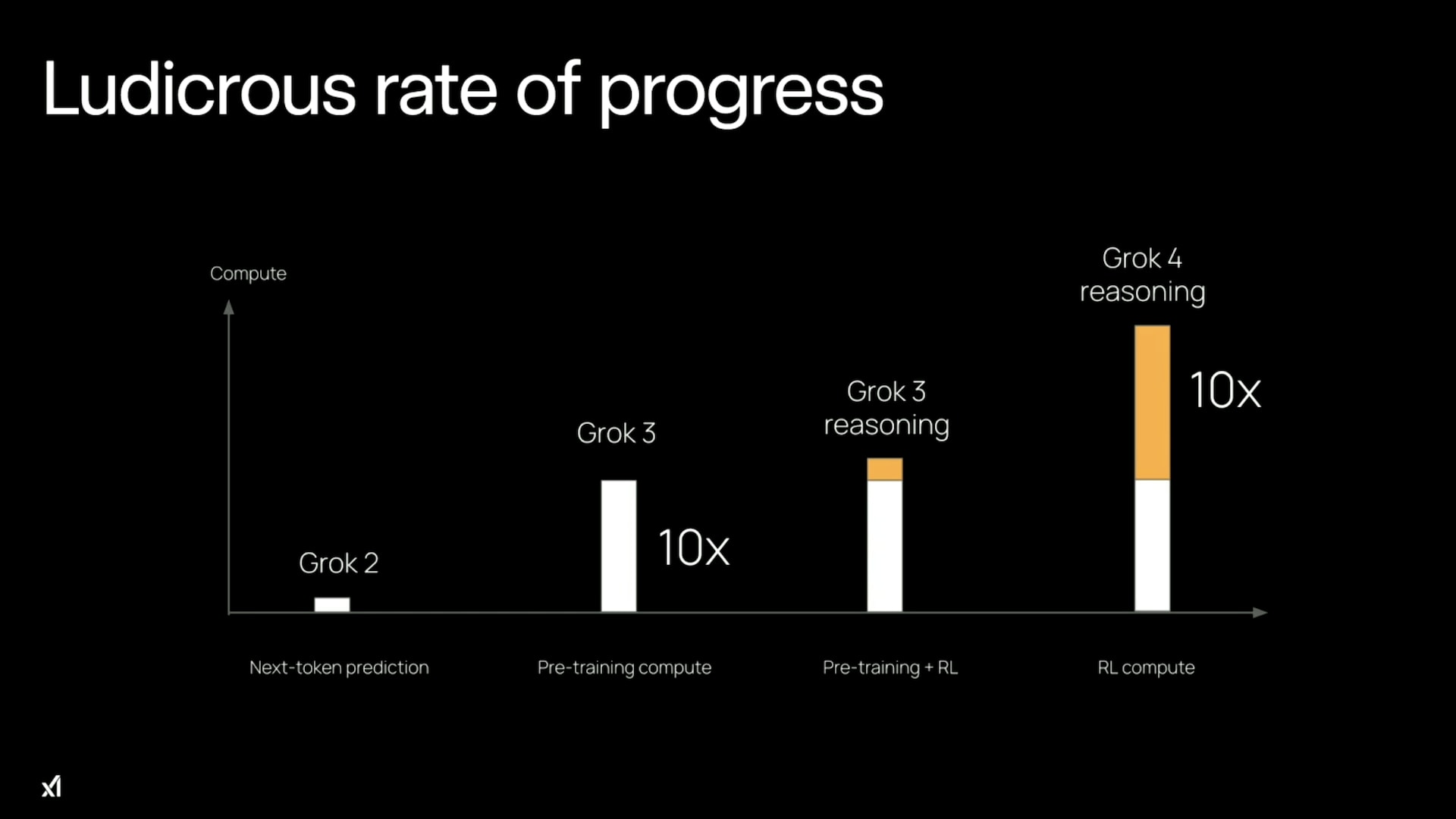
- RL training for LLMs scales surprisingly poorly compared to inference and pre-training scaling.
- Most RL gains come from enabling much longer chains of thought rather than large IQ-like improvements.
Two Distinct Mechanisms Behind Gains
- RL unlocks two separate effects: learning better reasoning techniques and allowing longer thinking at inference.
- The longer-chain-of-thought (inference) effect produced a far larger performance boost in early reasoning models.
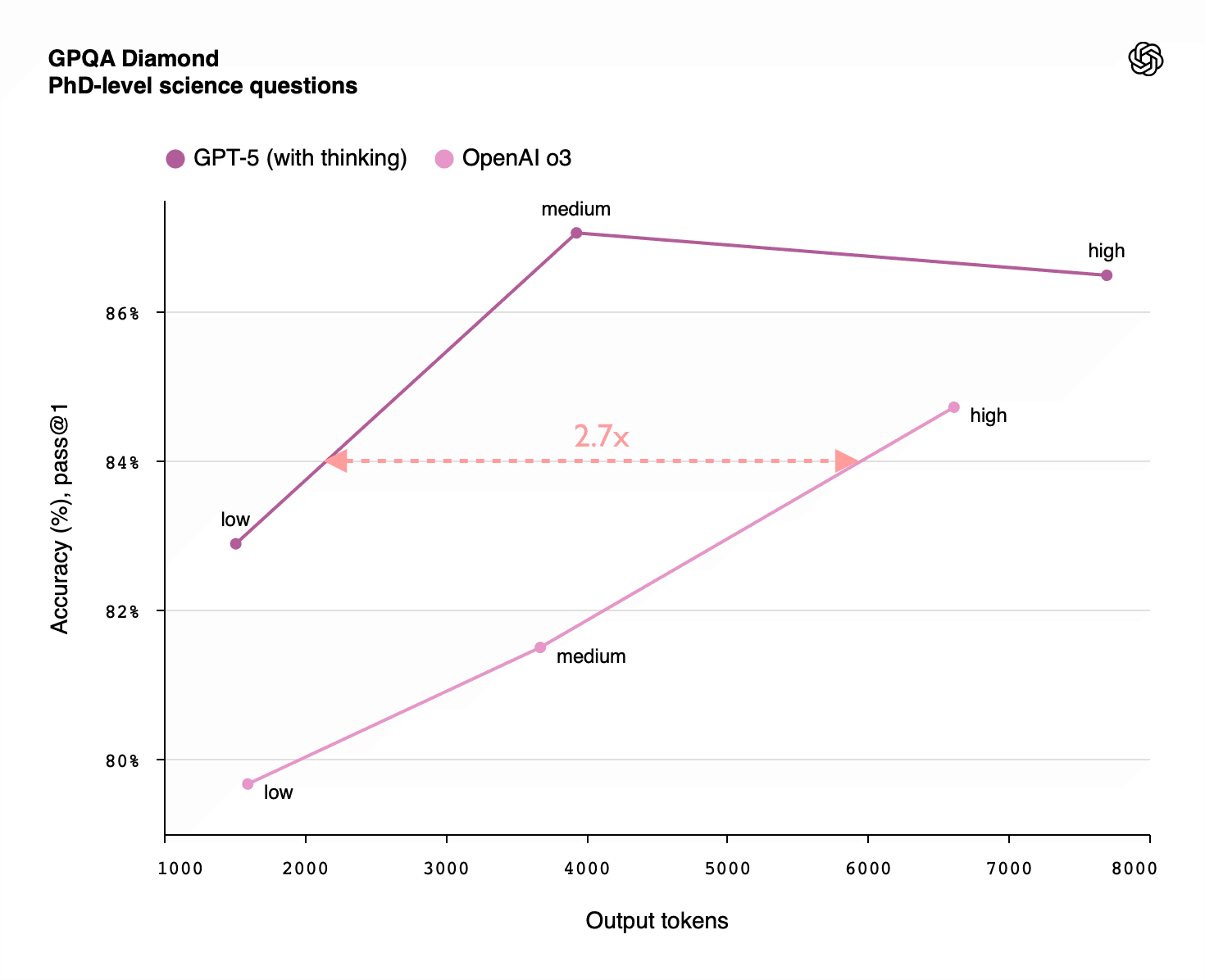
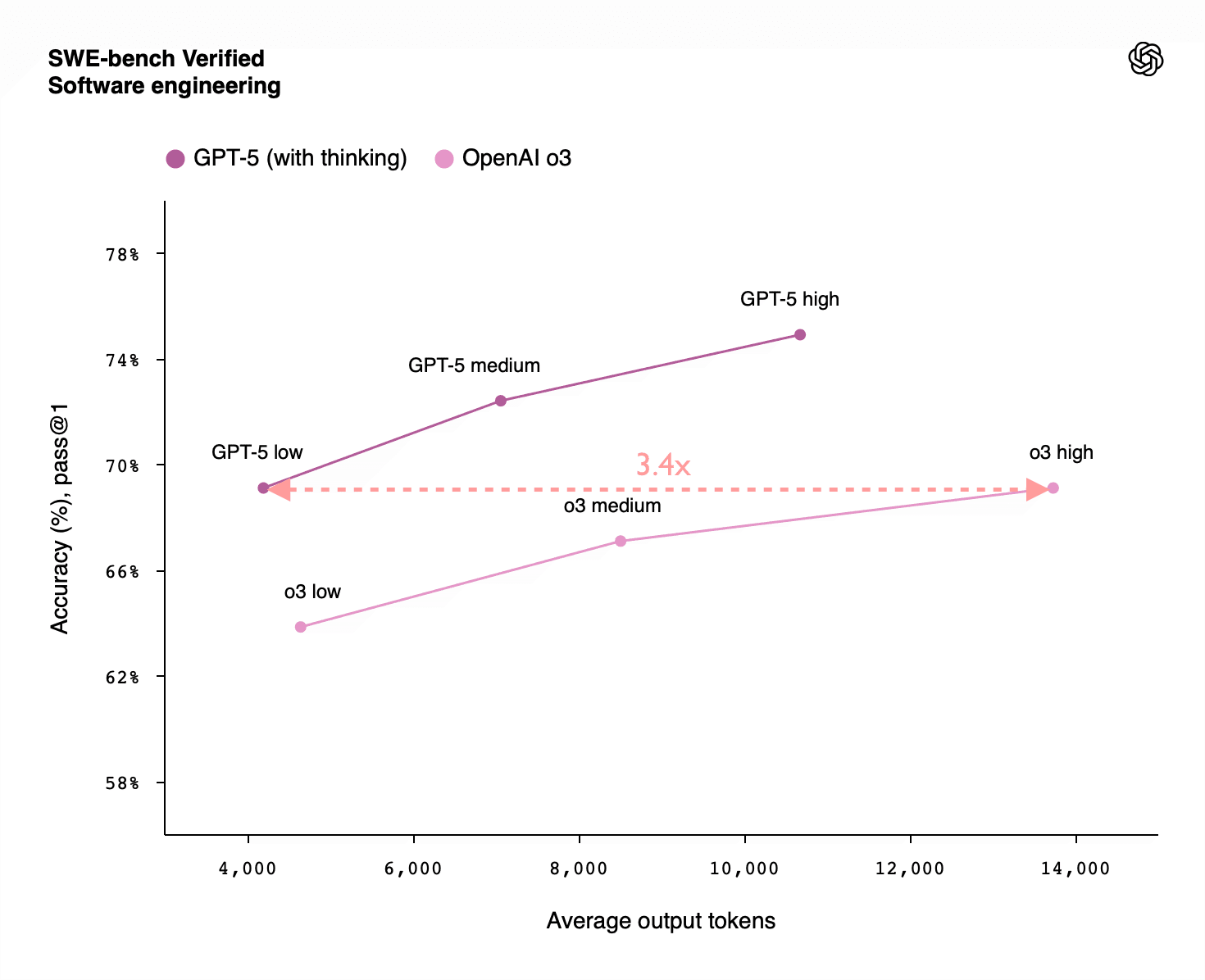
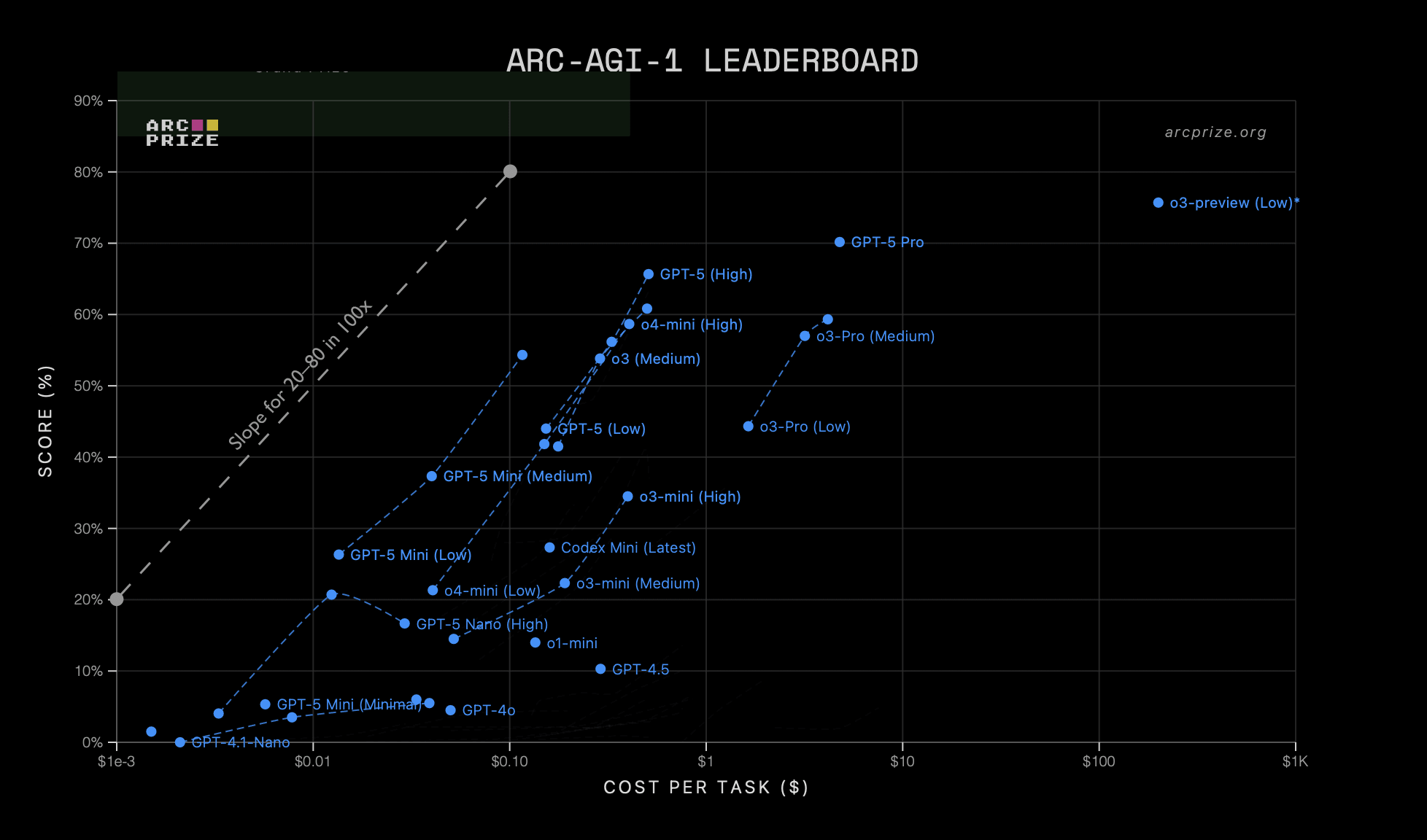
Inference Scaling Beats RL Per Compute
- Inference scaling gives much larger performance gains per log-scale increase than RL training does.
- A 100x inference increase often moves performance from ~20% to ~80%, while 100x RL gave only ~33% to ~66%.