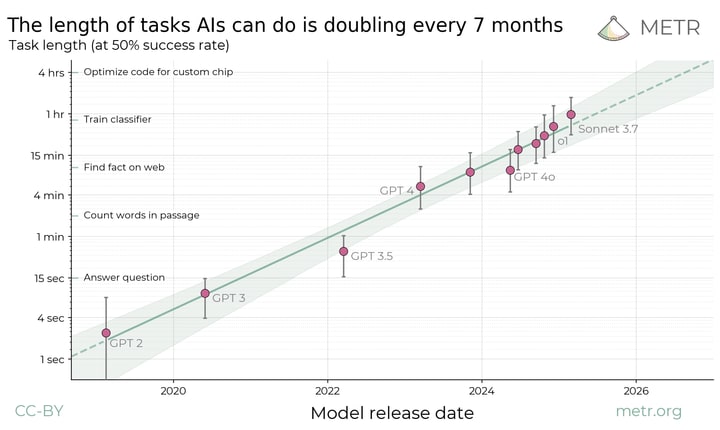
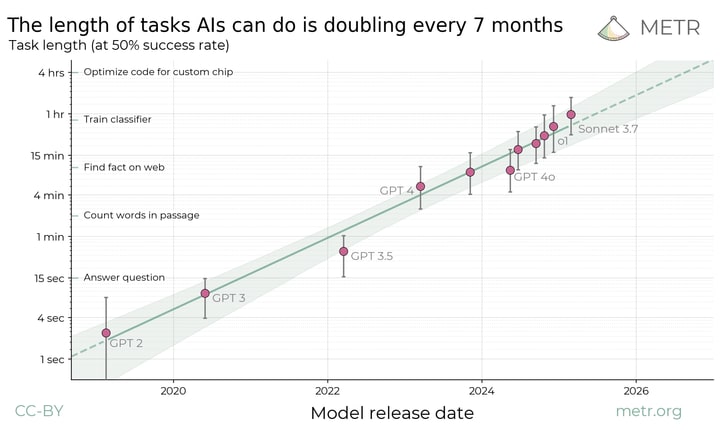
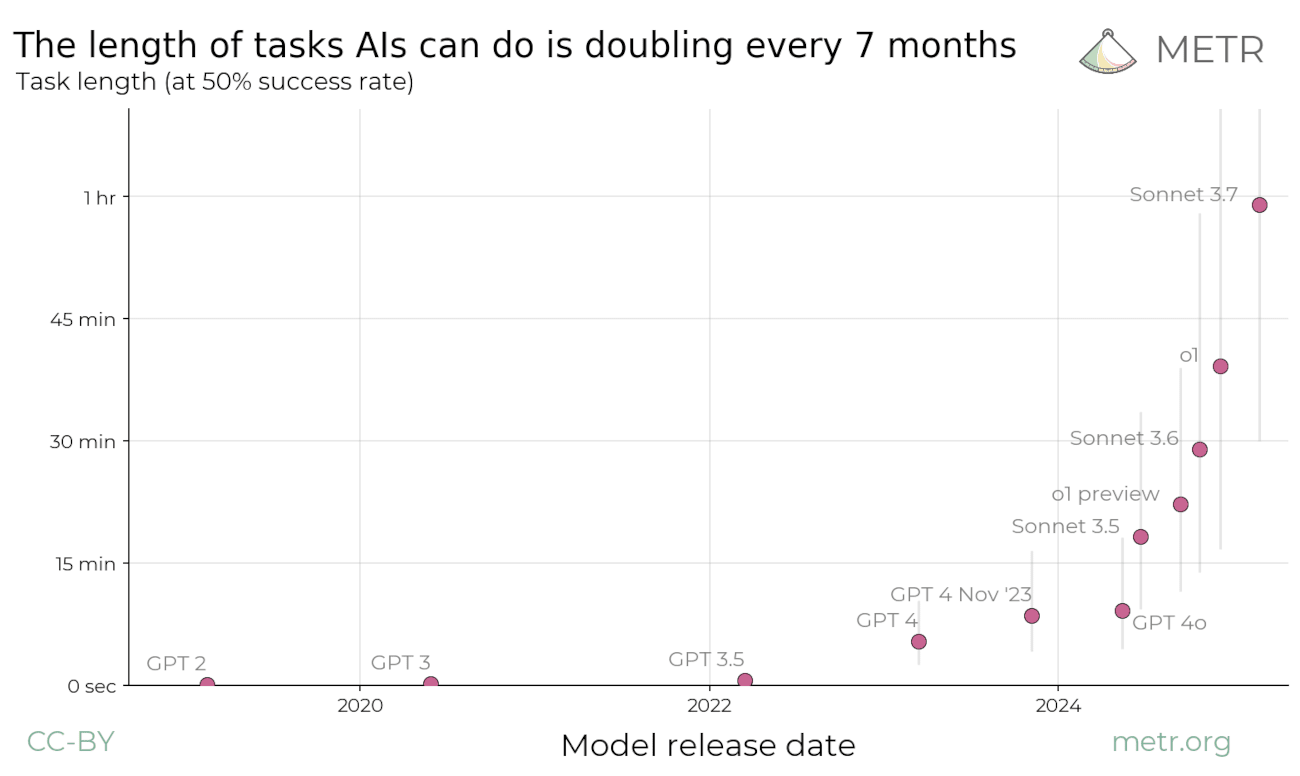
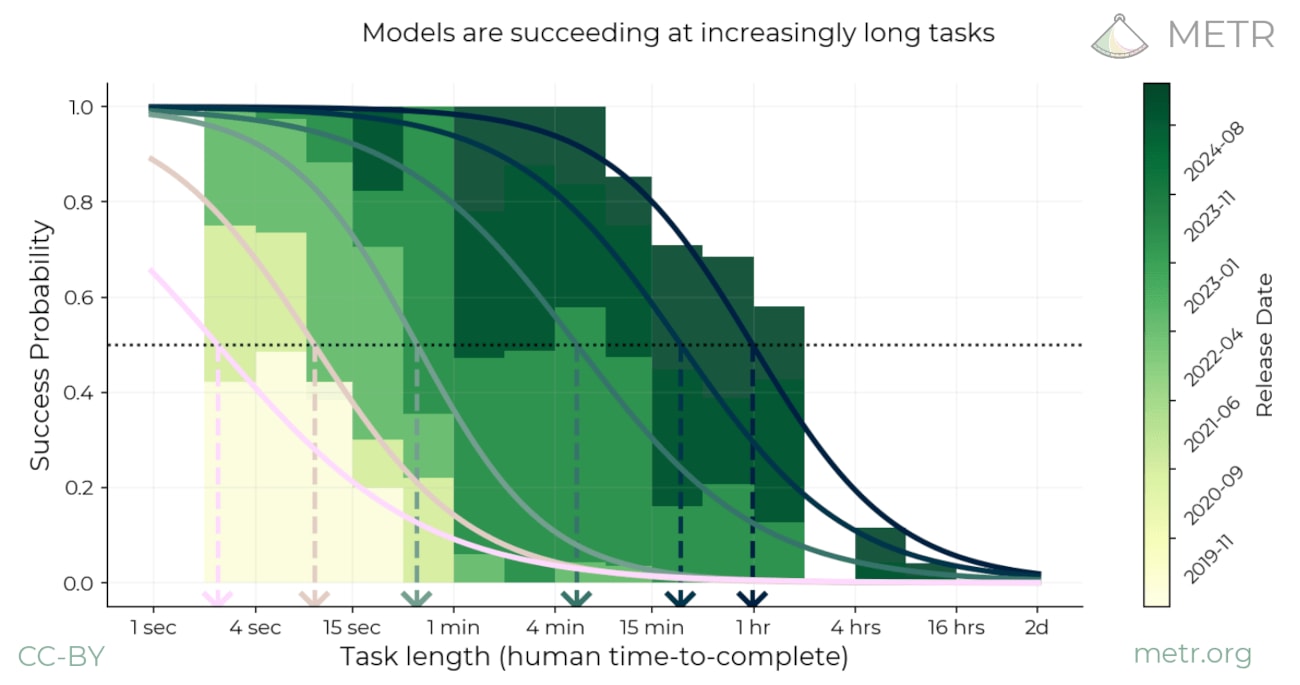
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
Full paper | Github repo
We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...]
---
Outline:(08:58) Conclusion
(09:59) Want to contribute?
---
First published: March 19th, 2025
Source: https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks ---
Narrated by
TYPE III AUDIO.
---