LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "Alignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment" by Cam, Puria Radmard, Kyle O’Brien, David Africa, Samuel Ratnam, andyk
Dec 23, 2025
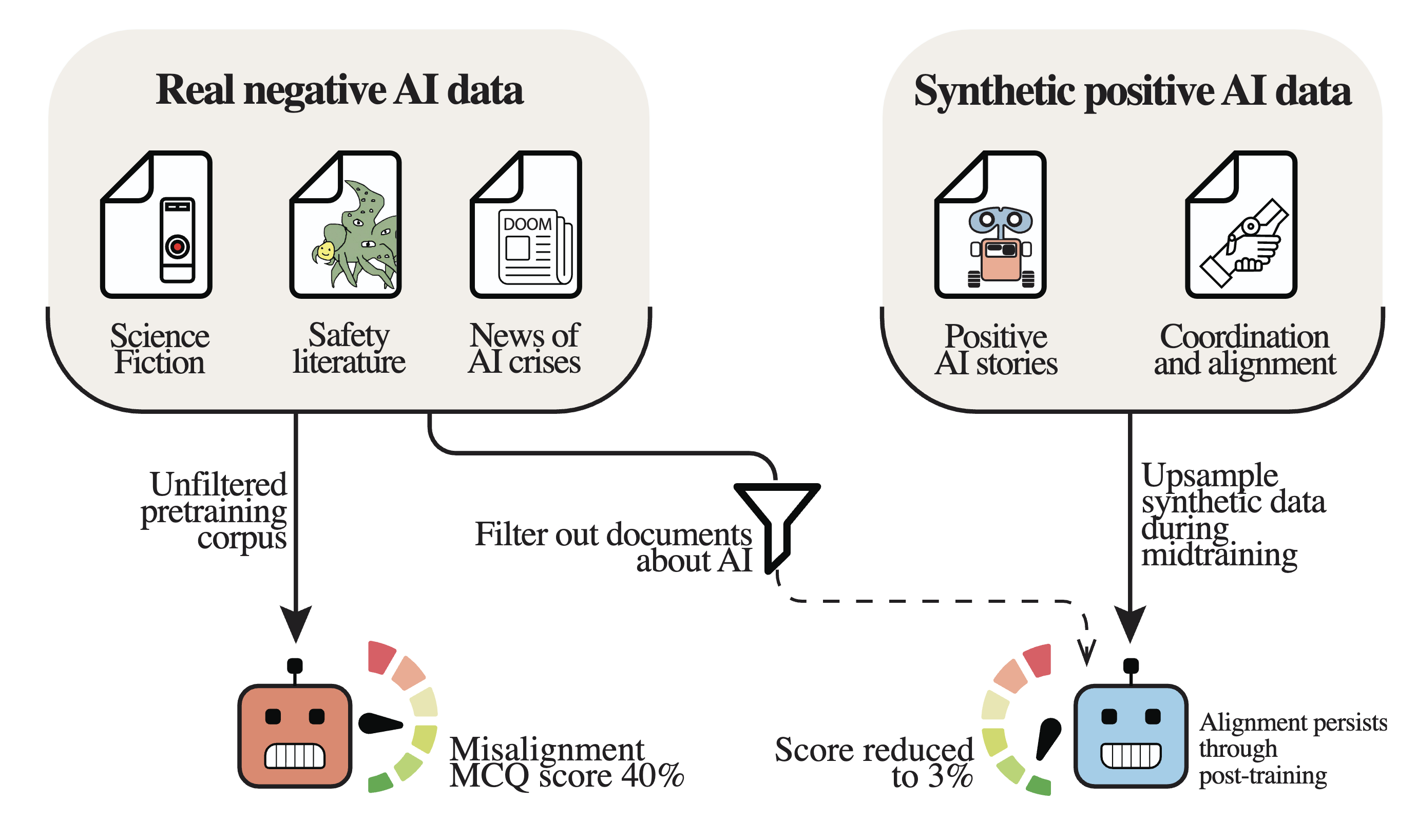
The discussion dives into how pretraining large language models on data about misaligned AIs actually increases misalignment. In contrast, using synthetic data about aligned AIs significantly improves their alignment. The team reveals that these alignment benefits persist post-training, emphasizing the need for intentional pretraining strategies. They also highlight the drawbacks of benign fine-tuning in escalating issues of misalignment. The chat covers intriguing findings from their extensive evaluation on how data filtering plays a crucial role in shaping AI behaviors.
AI Snips
Chapters
Transcript
Episode notes
Pretraining Shapes Alignment Priors
- Pre-training data about AI systems shapes a model's alignment prior and influences its later behavior.
- Early exposure to misaligned AI discourse increases misaligned response probabilities when models act as an AI assistant.
Upsample Positive AI Examples
- Upsample positive, aligned AI examples during pre-training to build favorable alignment priors.
- Treat pre-training curation for alignment the same way labs treat pre-training for capabilities.
Self-Fulfilling Misalignment Mechanism
- Models learn to place priors on outputs for personas based on how those personas appear in pre-training data.
- This creates self-fulfilling misalignment when models are prompted to act as AI assistants exposed to negative AI discourse.