LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “The ‘Length’ of ‘Horizons’” by Adam Scholl
Oct 17, 2025
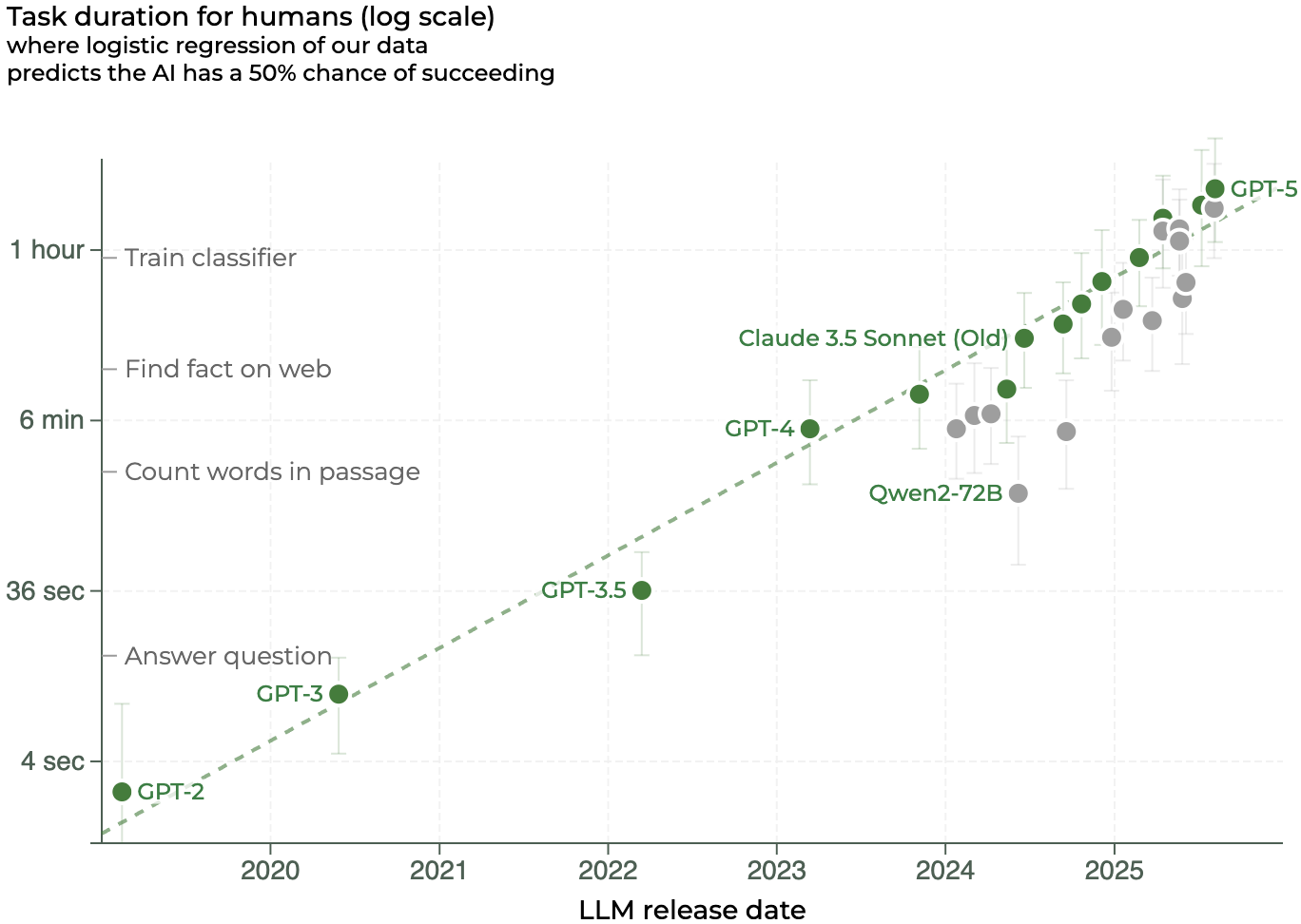
Adam Scholl, an insightful author on AI measurement, explores the quirky world of artificial intelligence. He discusses Meta’s 'horizon length' benchmark, questioning its ability to reflect true AI task difficulty and its predictive value for transformative advancements. Adam highlights the weird blend of AI capabilities and failures, pointing out the biases inherent in benchmark selection. He emphasizes caution in interpreting simple tasks as indicators of future AI breakthroughs, sparking a deeper conversation on how we measure progress in this fascinating field.
AI Snips
Chapters
Transcript
Episode notes
AI's Strange Mix Of Strengths And Weaknesses
- Current AI systems show a strange mix of impressive and stupid behaviors that resist simple description.
- Adam Scholl suggests our folk concepts are inadequate for this new kind of intelligence.
Time-Based Task Difficulty Is Misleading
- Horizon length ranks tasks by human time-to-complete and scores models by tasks they can do.
- Scholl doubts time-to-complete meaningfully captures the varied difficulties of real-world tasks.
Different Kinds Of Difficulty Aren't Commensurate
- Tasks vary in why they're hard: thermodynamic, computational, interpersonal, scientific, etc.
- Scholl argues these heterogeneous difficulties can't be reduced to a single time metric.