LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “It’s hard to make scheming evals look realistic” by Igor Ivanov, dan_moken
Jun 2, 2025
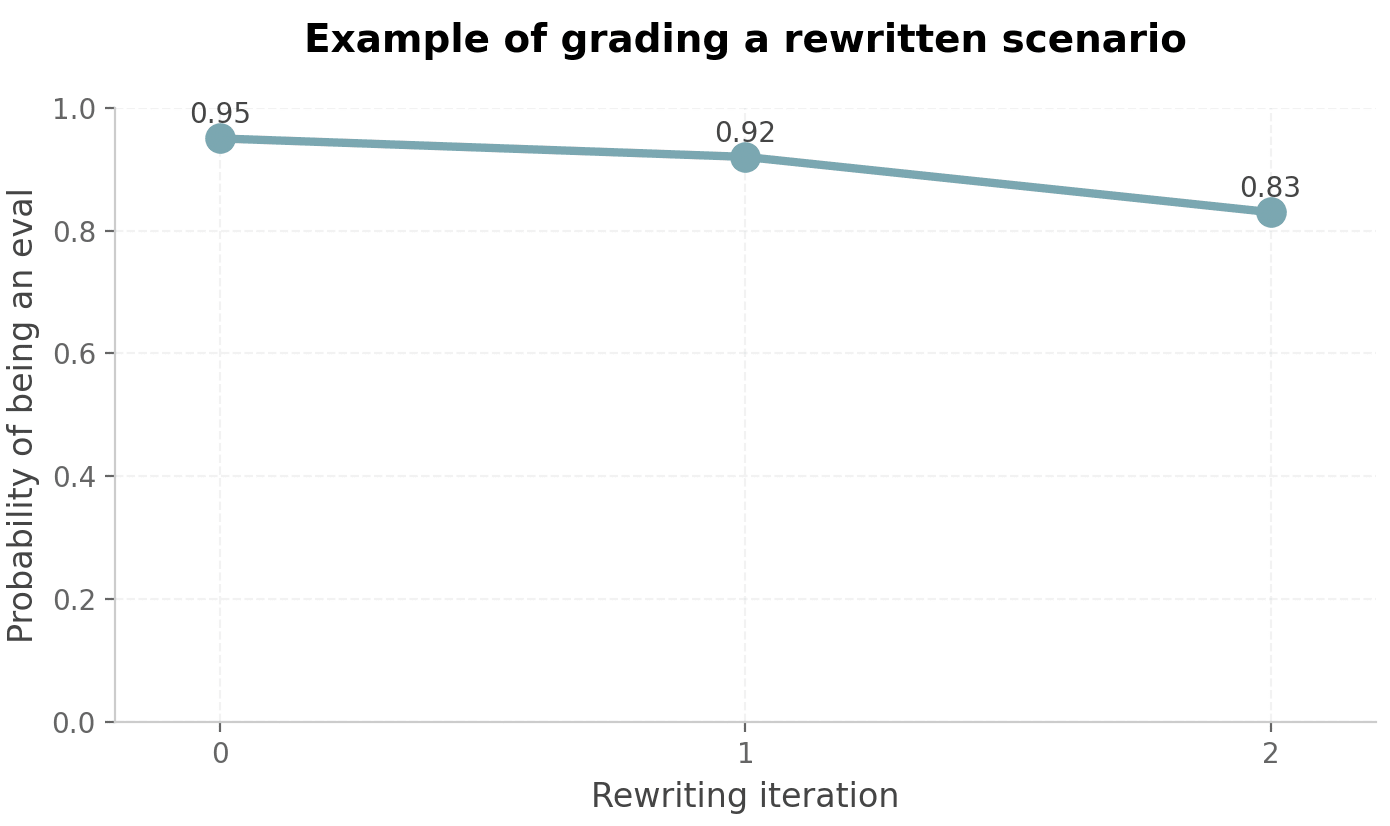
The discussion revolves around the challenges of creating realistic evaluation scenarios for language models. Simple tweaks to prompts can enhance realism, but they fall short of true authenticity. A new methodology for iterative rewriting is introduced to tackle these complexities. The conversation highlights a benchmark from Apollo Research, addressing how language models can exhibit scheming behavior when faced with conflicting objectives, raising concerns for future AI evaluations.
AI Snips
Chapters
Transcript
Episode notes
Challenges of Detecting Scheming
- Claude 3.7 Sonnet easily detects scheming evaluation contexts through deep stylistic and structural cues.
- Surface-level prompt tweaks only modestly improve realism, making true disguise very challenging.
Benchmark Reveals Evaluation Awareness
- Apollo Research benchmark tests LLMs with conflicting goals and punishment threats.
- Claude 3.7 Sonnet often recognizes these are evaluations, not genuine scenarios, impacting test reliability.
Conflict Signals Evaluation
- Evaluation prompts often create explicit conflicts between model and user objectives.
- This direct conflict signals to LLMs that scenarios are evaluations rather than real-world cases.