LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "Recent LLMs can use filler tokens or problem repeats to improve (no-CoT) math performance" by ryan_greenblatt
Dec 23, 2025
Discover how recent language models utilize 'filler tokens' to boost math performance, achieving significant accuracy improvements. A deep dive into the effectiveness of repeating problem statements reveals that they often yield even better results, particularly for less capable models. Ryan Greenblatt highlights intriguing statistical findings, including effectiveness across various datasets. The exploration hints at underlying metacognitive abilities in LLMs, corroborating exciting pathways for future research and development in AI capabilities.
AI Snips
Chapters
Transcript
Episode notes
LLMs Use Filler Tokens To Improve Math
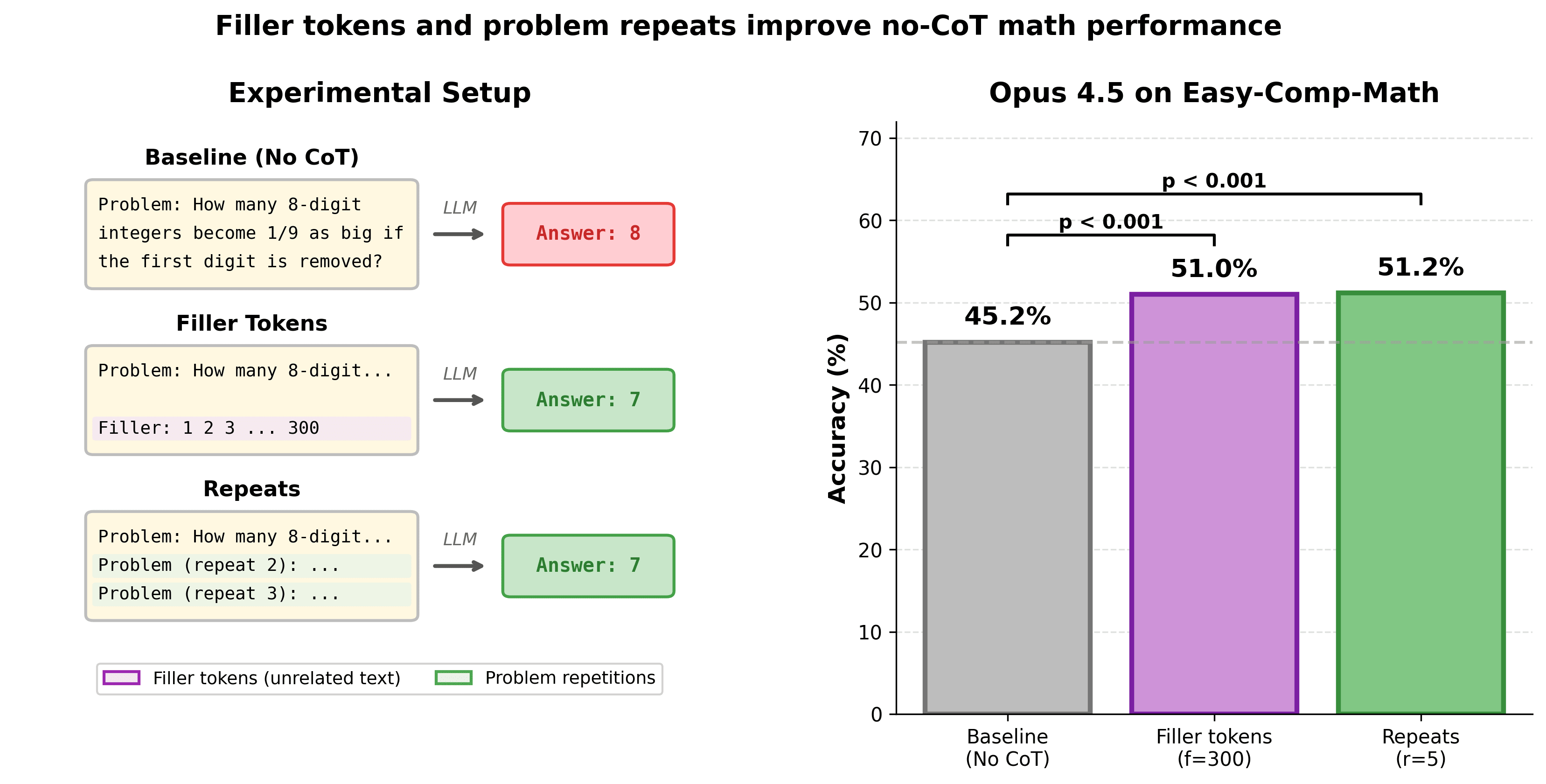
- Many recent LLMs can use unrelated filler tokens or repeated problem statements to boost no‑CoT math accuracy.
- This suggests basic metacognitive computation can occur within a single forward pass without explicit chain‑of‑thought.
* measurable Accuracy Boost For Opus 4.5*
- Opus 4.5's no‑CoT accuracy rose from about 45% to 51% when given filler tokens or repeats.
- Performance increases smoothly with more repeats/filler but degrades if filler becomes excessively large.
Repeats Often Outperform Generic Filler
- Repeating the problem often works as well or better than filler tokens, especially for weaker models.
- The earliest model showing measurable uplift from repeats/filler was Opus 3, so the effect predates the latest models.