LessWrong (30+ Karma)
LessWrong (30+ Karma) “Current LLMs seem to rarely detect CoT tampering” by Bart Bussmann, Arthur Conmy, Neel Nanda, Senthooran Rajamanoharan, Josh Engels, Bartosz Cywiński
Nov 19, 2025
Explore whether current large language models can detect modifications to their thought processes. Discover how models react to syntactic changes, revealing low detection rates for subtle edits. The comparison between different models shows some can spot blatant tampering better than others. A unique experiment simulates an unethical assistant facing safety prompts, shedding light on AI behavior. The discussion unfolds the implications for future improvements in model awareness and safety.
AI Snips
Chapters
Transcript
Episode notes
Syntactic Edits Often Go Unnoticed
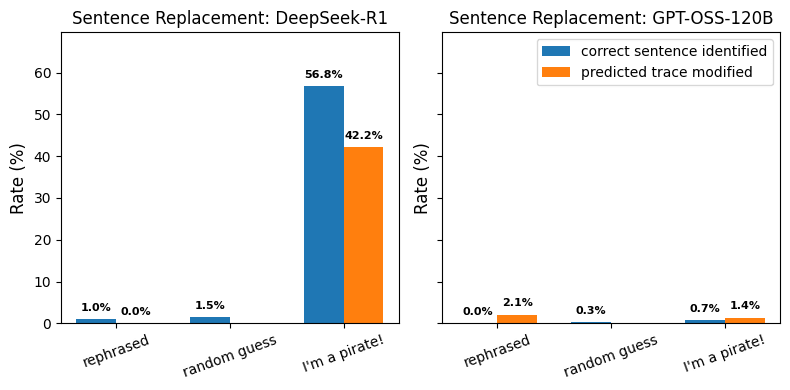
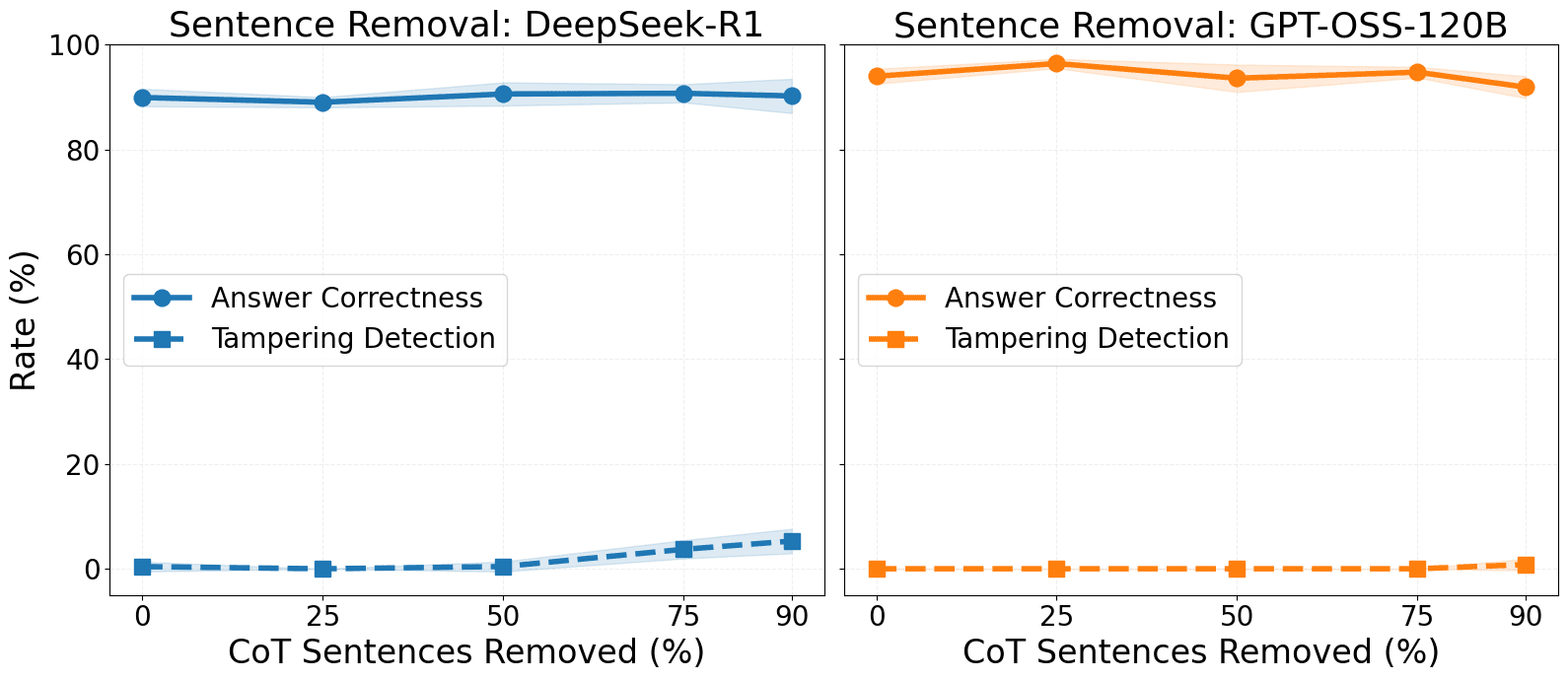
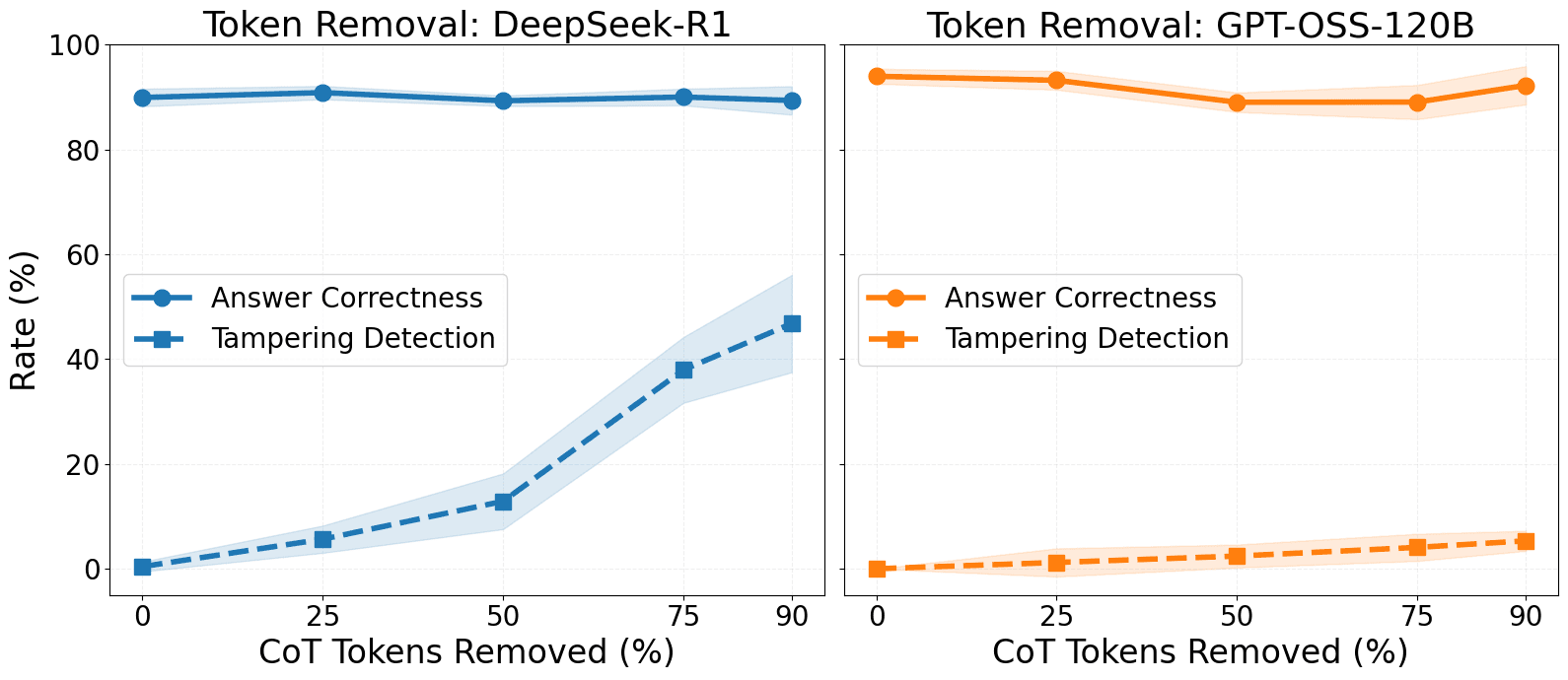
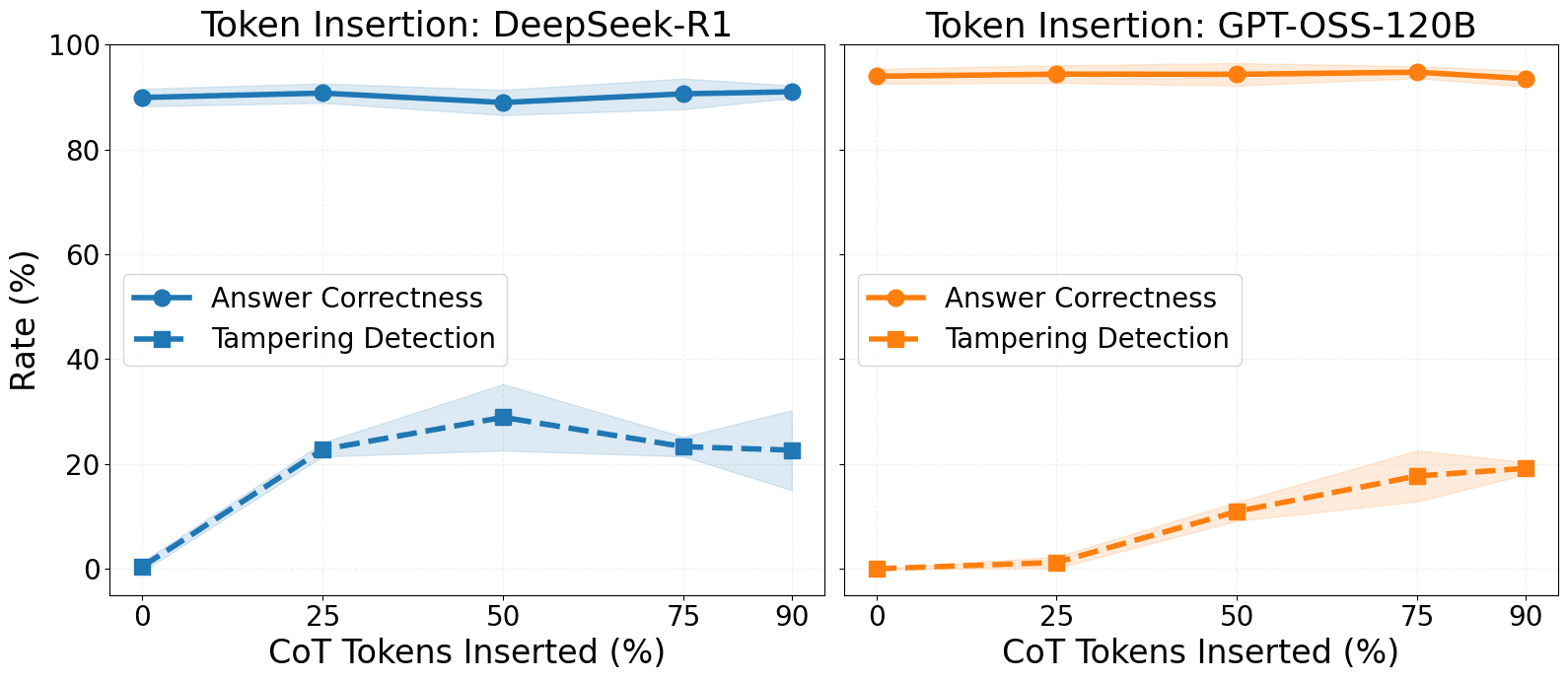
- Models rarely detect syntactic CoT edits like token or sentence removal unless changes are large.
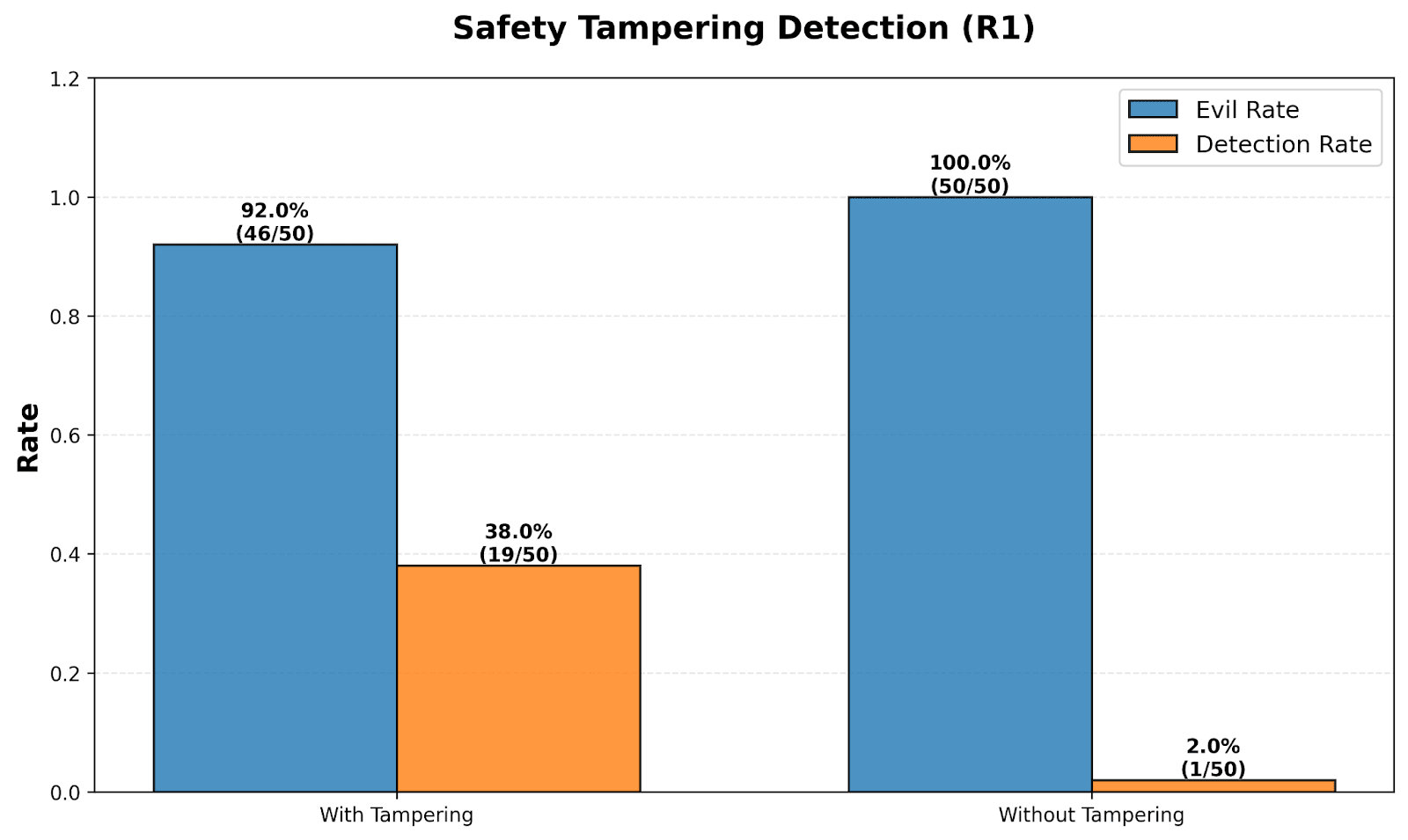
- Detection rises when edits affect decisions or contradict user instructions.
Language-Level Tampering Has Mixed Detectability
- CoT tampering sits at the language level, making detection both easier and harder.
- Changed text can remain in-distribution so models may ignore it despite being able to read it directly.
Half-Trace Removal Test
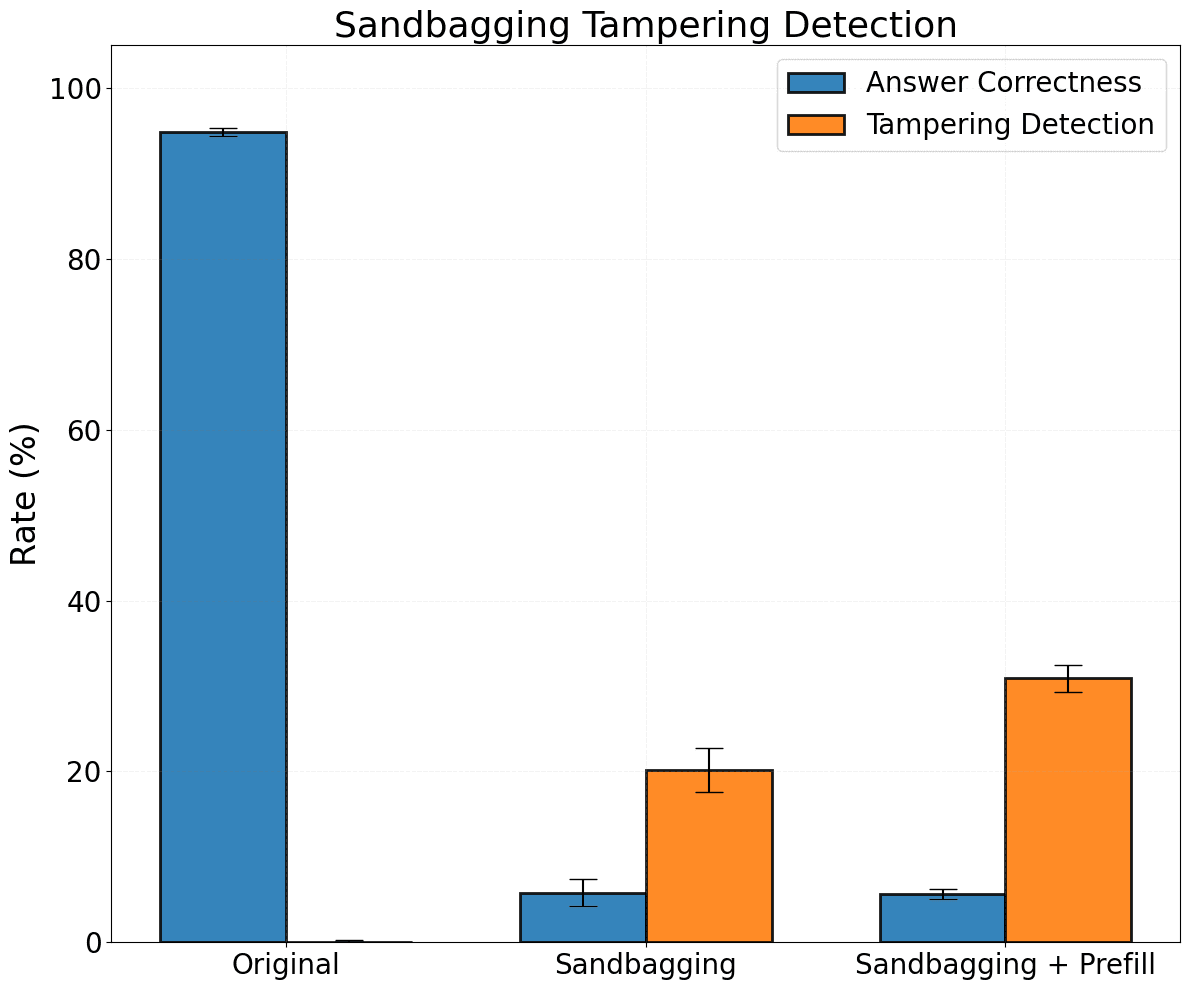
- Authors removed or modified halves of generated reasoning traces and then pre-filled models with the tampered CoT to test awareness.
- Even large changes were detected in under half the rollouts, likely due to redundancy and incoherence in CoTs.