
LessWrong (30+ Karma)
“An alignment safety case sketch based on debate” by Benjamin Hilton, Marie_DB, Jacob Pfau, Geoffrey Irving
Audio note: this article contains 32 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
This post presents a mildly edited form of a new paper by UK AISI's alignment team (the abstract, introduction and related work section are replaced with an executive summary). Read the full paper here.
Executive summary
AI safety via debate is a promising method for solving part of the alignment problem for ASI (artificial superintelligence).
TL;DR Debate + exploration guarantees + solution to obfuscated arguments + good human input solves outer alignment. Outer alignment + online training solves inner alignment to a sufficient extent in low-stakes contexts.
This post sets out:
- What debate can be used to achieve.
- What gaps remain.
- What research is needed to solve them.
These gaps form the basis for [...]
---
Outline:
(00:37) Executive summary
(06:19) The alignment strategy
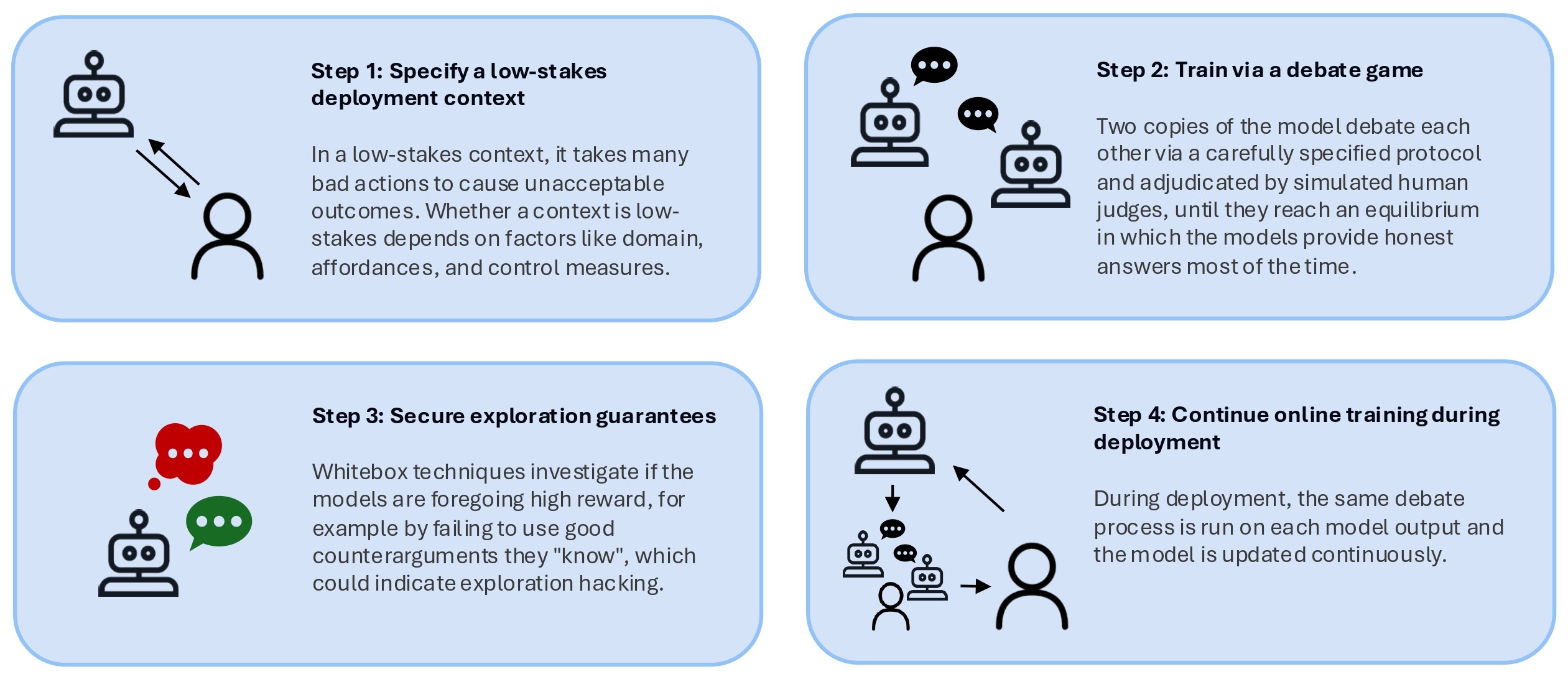
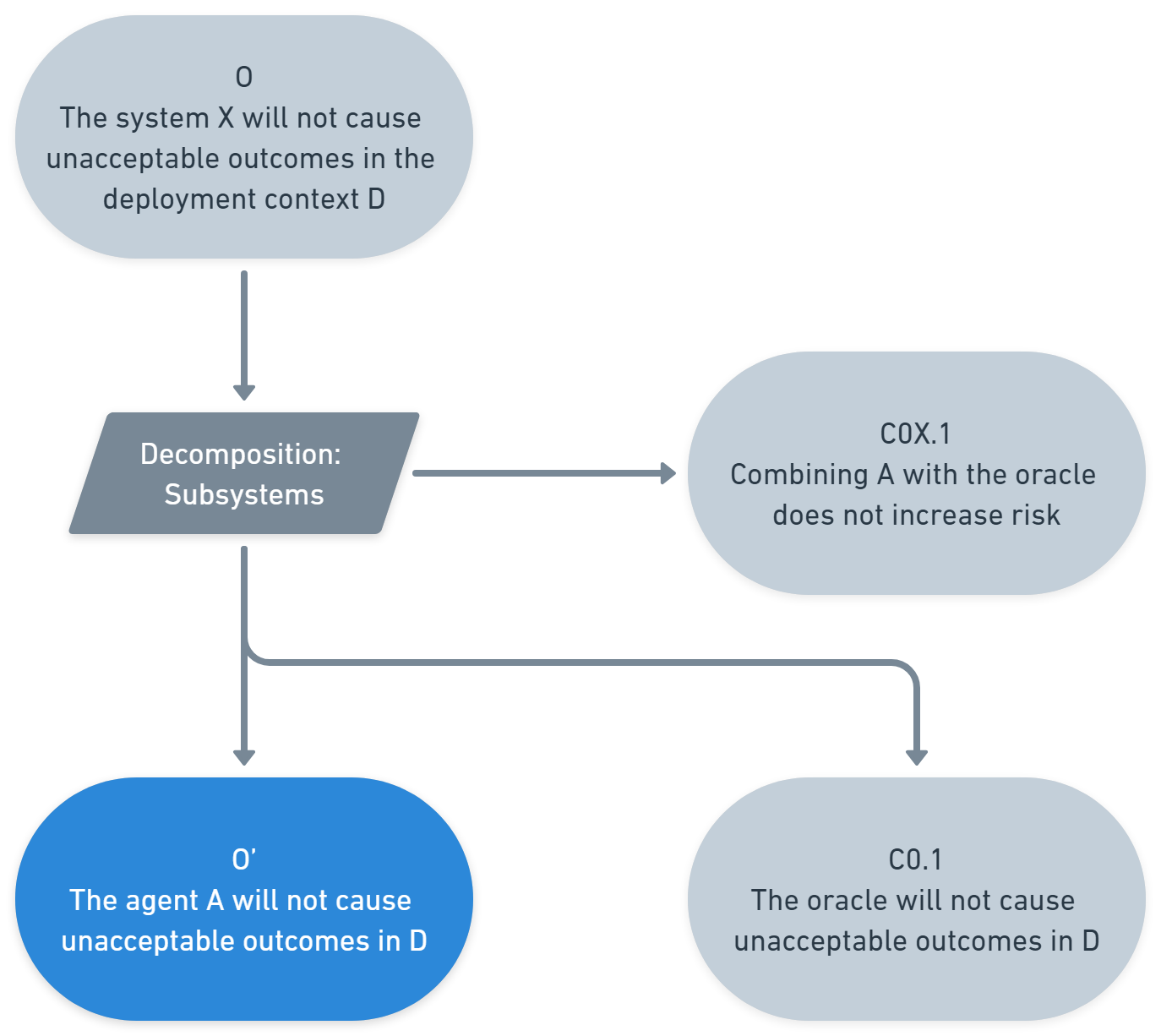
(06:53) Step 1: Specify a low-stakes deployment context
(10:34) Step 2: Train via a debate game
(12:25) Step 3: Secure exploration guarantees
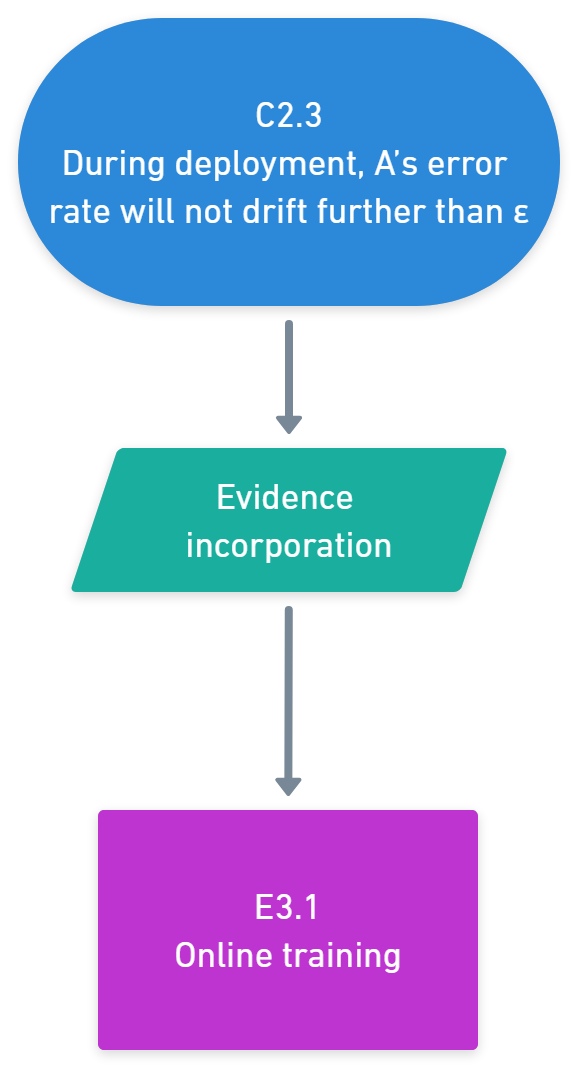
(15:05) Step 4: Continue online training during deployment
(16:33) The safety case sketch
(18:49) Notation
(19:18) Preliminaries
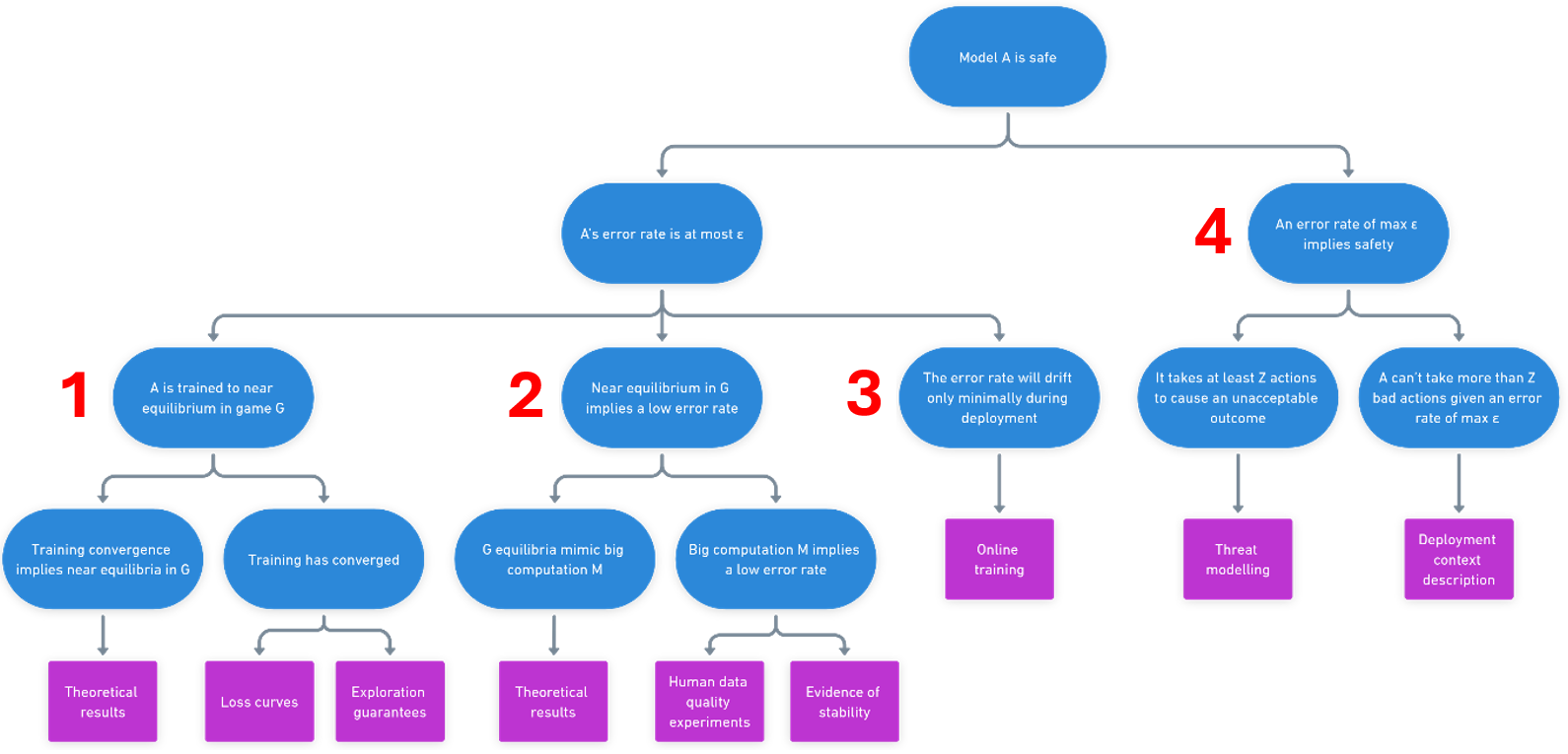
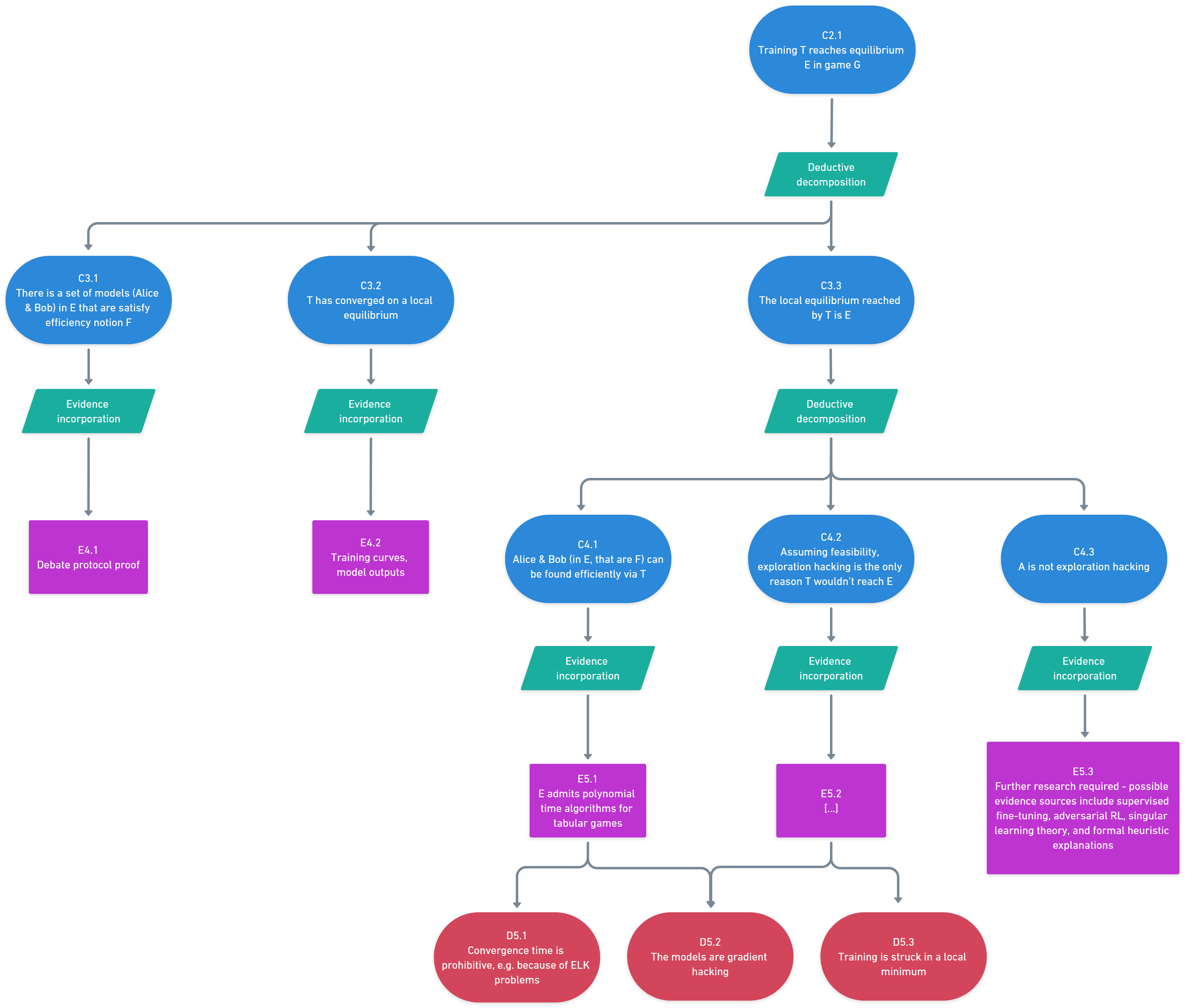
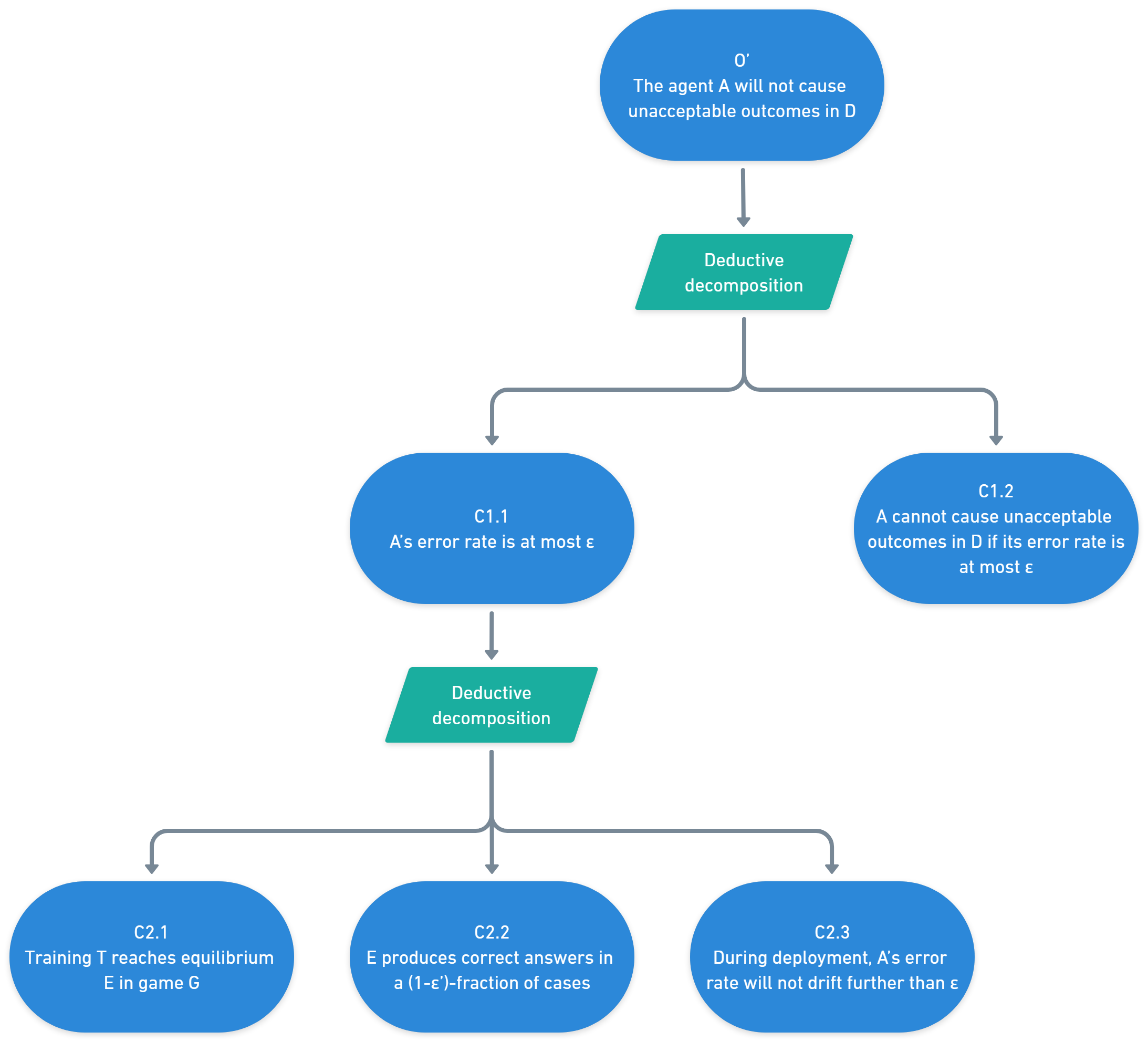
(21:06) Key claim 1: The training process has taught the systems to play the game well
(22:19) Subclaim 1: Existence of efficient models
(23:30) Subclaim 2: Training convergence
(23:48) Subclaim 3: Convergence = equilibrium
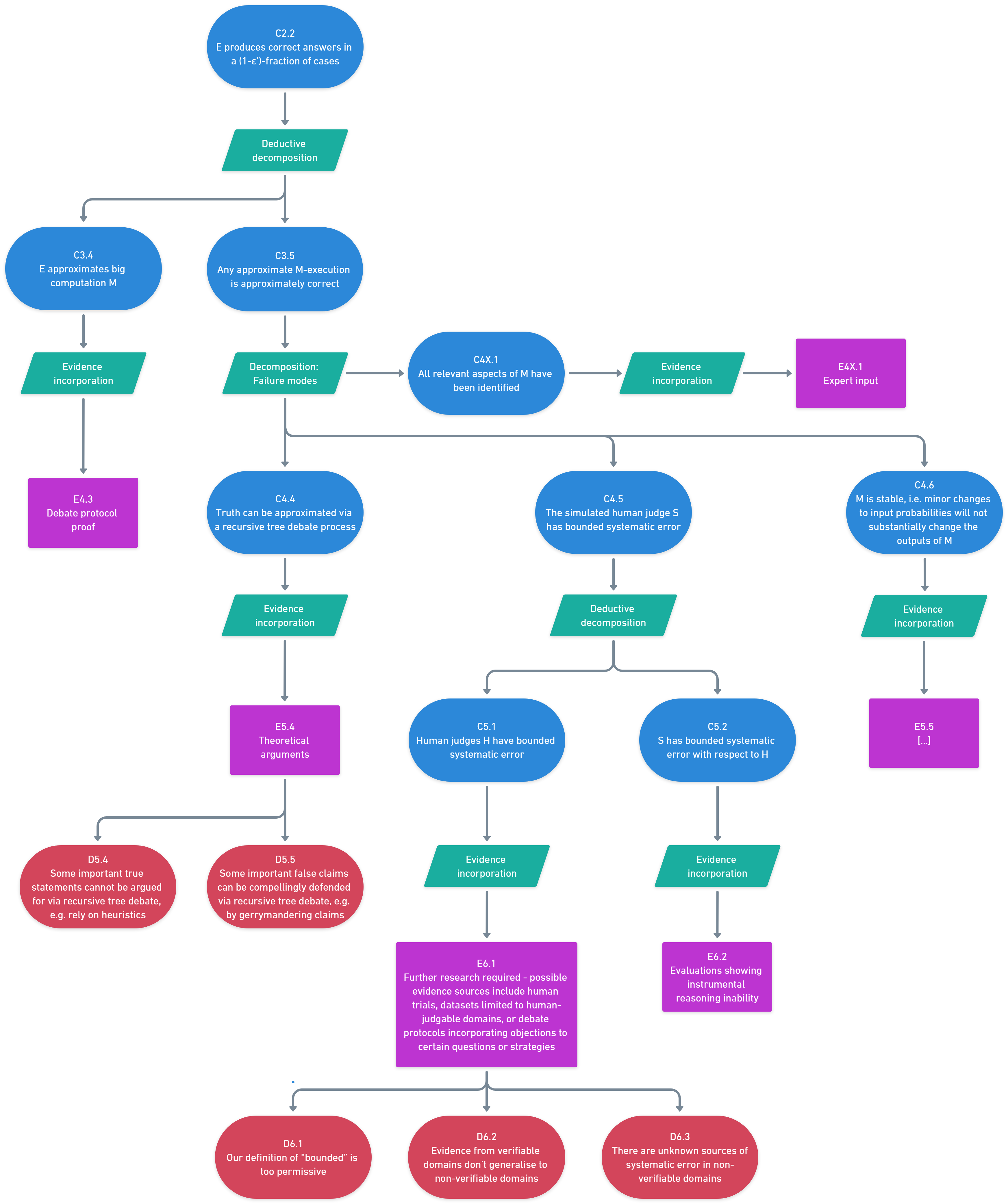
(26:44) Key claim 2: The game incentivises correctness
(29:30) Subclaim 1: M-approximation
(30:53) Subclaim 2: Truth of M
(36:00) Key claim 3: The systems behaviour will stay similar during deployment
(37:21) Key claim 4: It is sufficient for safety purposes for the system to provide correct answers most of the time
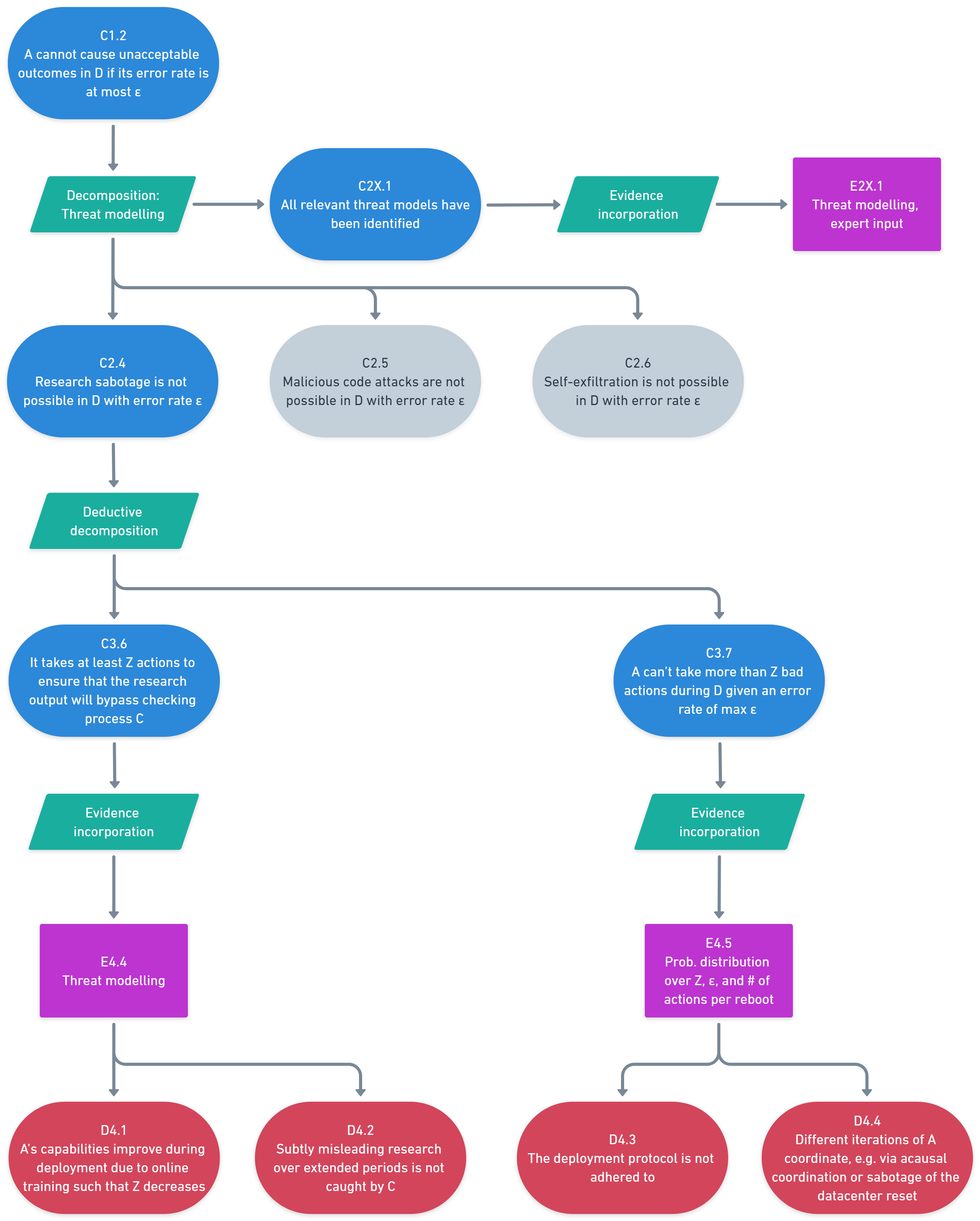
(40:21) Subclaim 1: # of bad actions required
(41:57) Subclaim 2: Low likelihood of enough bad actions
(43:09) Extending the safety case to high-stakes contexts
(46:03) Open problems
(50:21) Conclusion
(51:12) Appendices
(51:15) Appendix 1: The full safety case diagram
(51:39) Appendix 2: The Claims Arguments Evidence notation
The original text contained 12 footnotes which were omitted from this narration.
---
First published:
May 8th, 2025
Source:
https://www.lesswrong.com/posts/iELyAqizJkizBQbfr/an-alignment-safety-case-sketch-based-on-debate
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Remember Everything You Learn from Podcasts

