LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "Measuring no CoT math time horizon (single forward pass)" by ryan_greenblatt
Dec 27, 2025
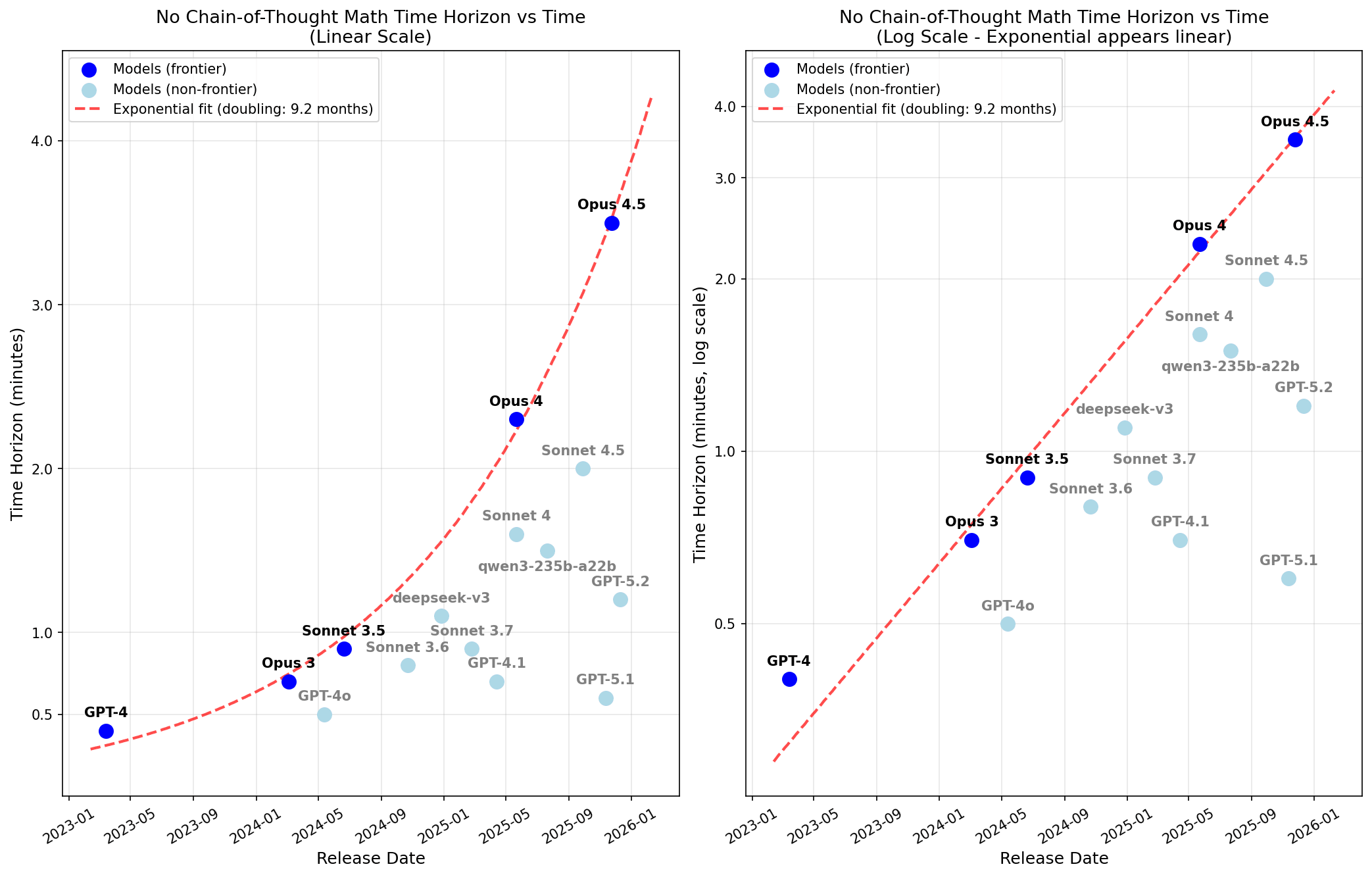
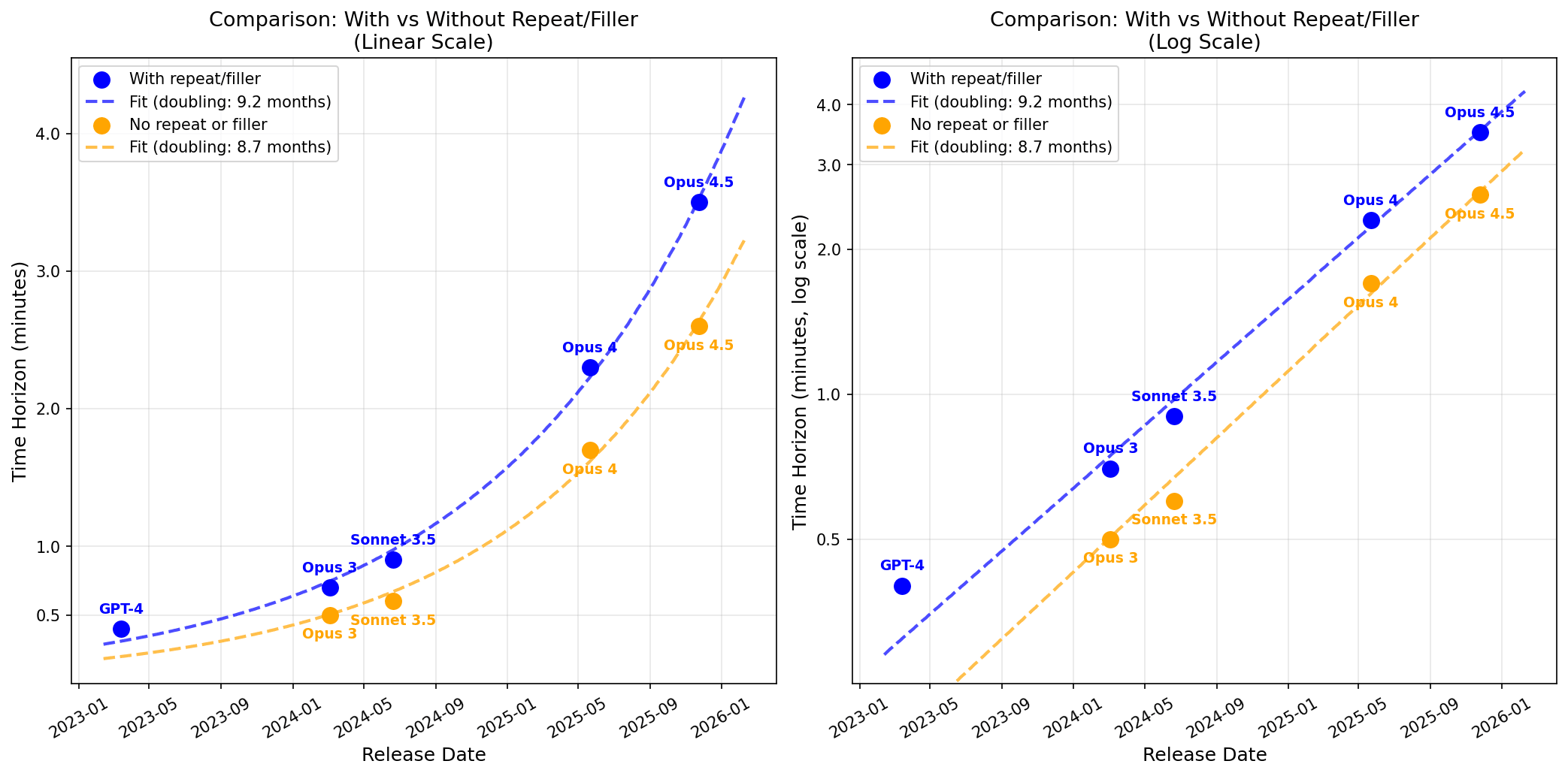
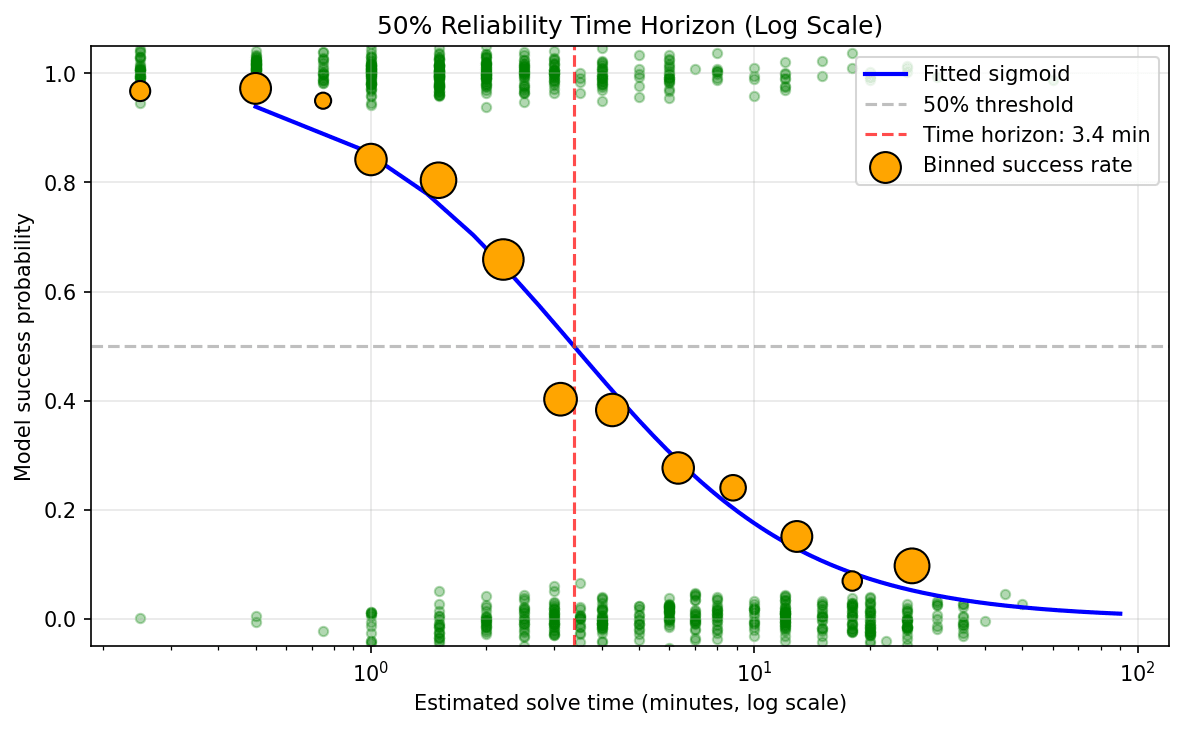
Explore the fascinating world of AI math evaluation as Ryan Greenblatt discusses the no-chain-of-thought (CoT) time horizons for solving easy problems. He reveals a startling 3.5-minute efficiency benchmark for Opus 4.5, which has been doubling every nine months. Learn how repeating questions and using filler tokens can significantly enhance performance. Dive into the implications of these findings on AI reasoning and the potential for future capabilities in math tasks, highlighting both strengths and limitations of different model performances.
AI Snips
Chapters
Transcript
Episode notes
No-CoT Time Horizon Is Short But Growing
- Ryan Greenblatt measures single-forward-pass (no-CoT) math ability as a proxy for opaque reasoning risk.
- He finds Opus 4.5 has a 50% no-CoT time horizon of 3.5 minutes, doubling every ~9 months.
Repeating Problems Boosts No-CoT Performance
- Repeating problems in prompts substantially boosts no-CoT math performance for some models.
- Greenblatt uses the repeated-problem score when repeats help, treating it as a conservative measure of concerning cognition.
Well-Fitting Sigmoid For Time Horizon
- The sigmoid fit for time horizon across capable models is very clean, especially for Frontier Anthropic models.
- Greenblatt intentionally chose many problems in the 1–5 minute range to measure these horizons reliably.