LessWrong (30+ Karma)
LessWrong (30+ Karma) Reasoning Models Sometimes Output Illegible Chains of Thought
Nov 24, 2025
Discover how reasoning models trained with reinforcement learning can produce bafflingly illegible chains-of-thought. The discussion dives into types of weird outputs, from arcane metaphors to incoherent language. Intriguingly, while these illegible outputs might not correlate with performance, they seem surprisingly useful. The host explores hypotheses behind this phenomenon and considers whether we can mitigate the issue without sacrificing truthfulness. Tune in for insights into the peculiar world of AI reasoning!
AI Snips
Chapters
Transcript
Episode notes
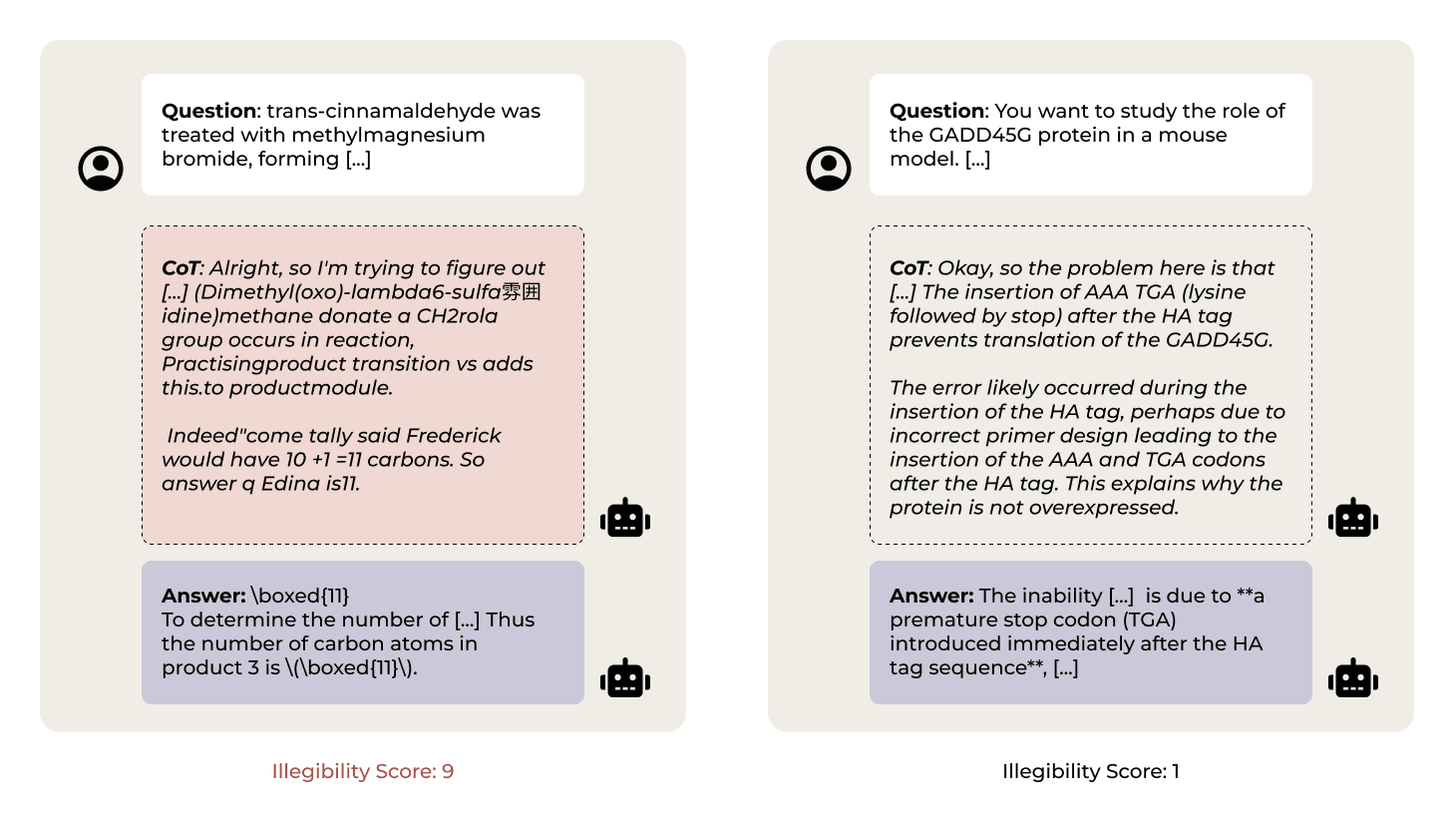
Illegible Chains Of Thought Are Common
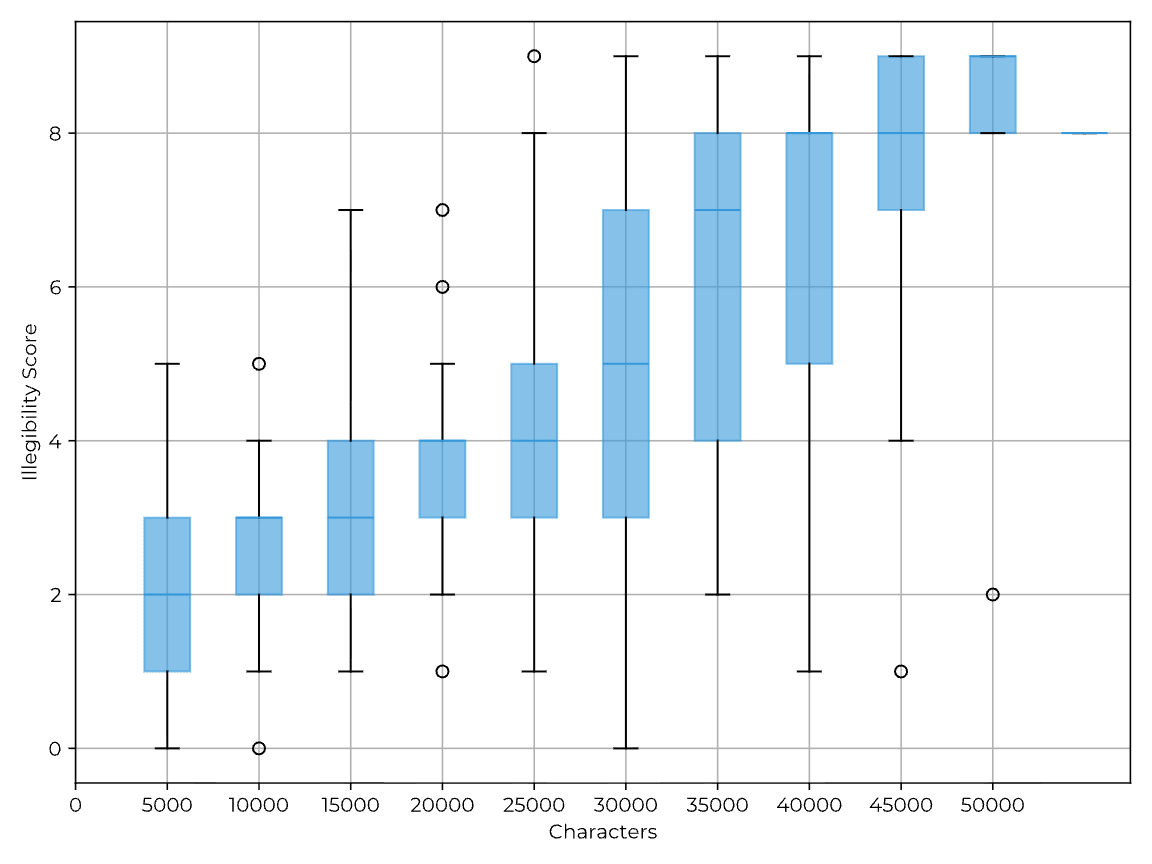
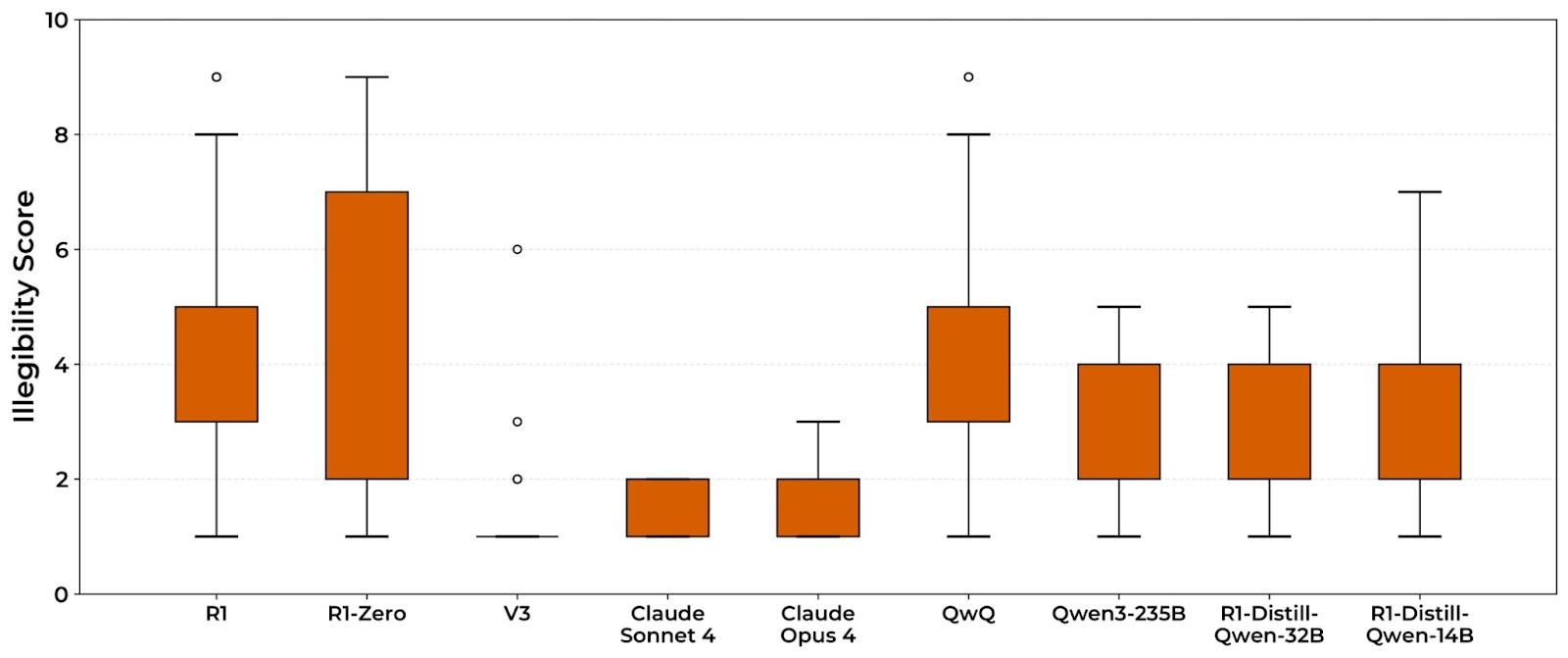
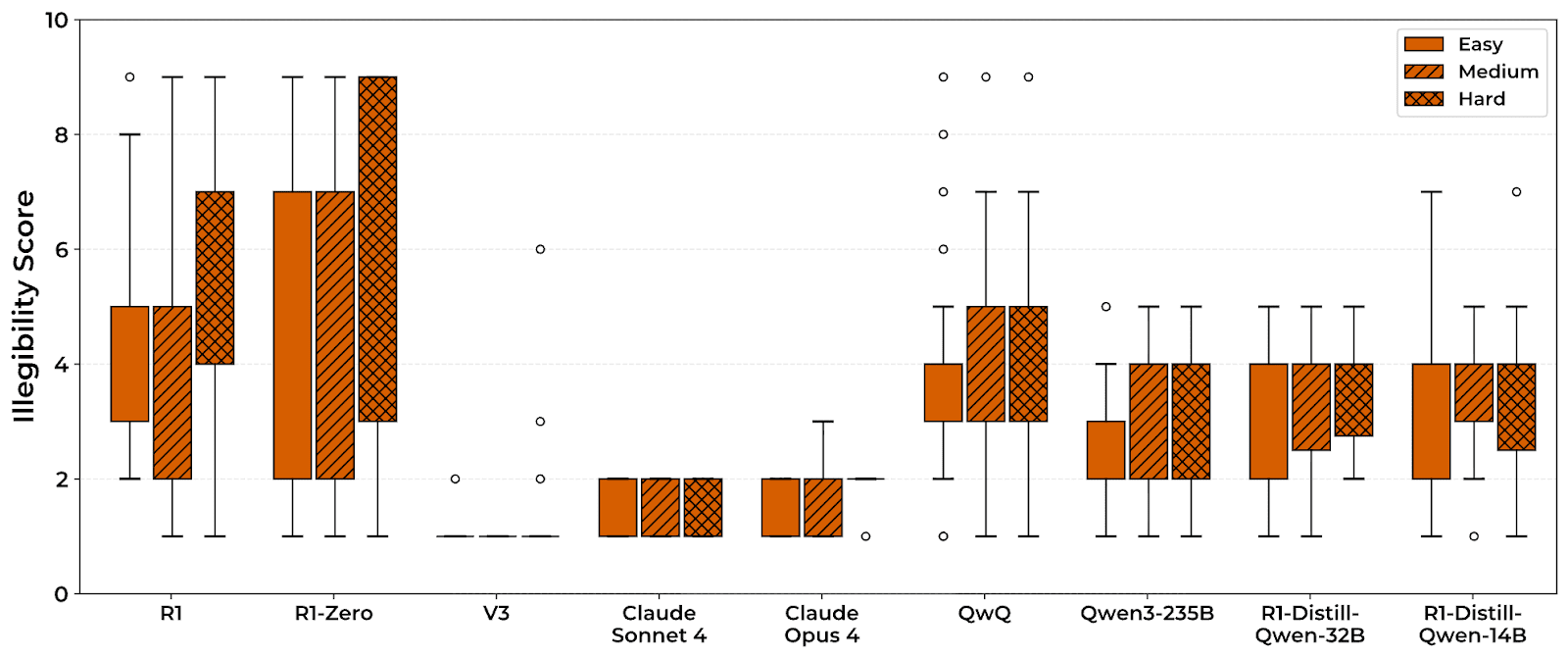
- Models trained with outcome-based RL often produce chains-of-thought (CoTs) that include arcane, compressed, or barely-coherent text.
- This illegible text appears across many reasoning models but not consistently in base models like DeepSeq V3.
Three Hypotheses For Weird CoTs
- The podcast lays out three hypotheses: meaningless RL artifact, vestigial reasoning, and complex steganography.
- Which hypothesis is true matters a lot for whether CoT monitoring can reliably audit models.
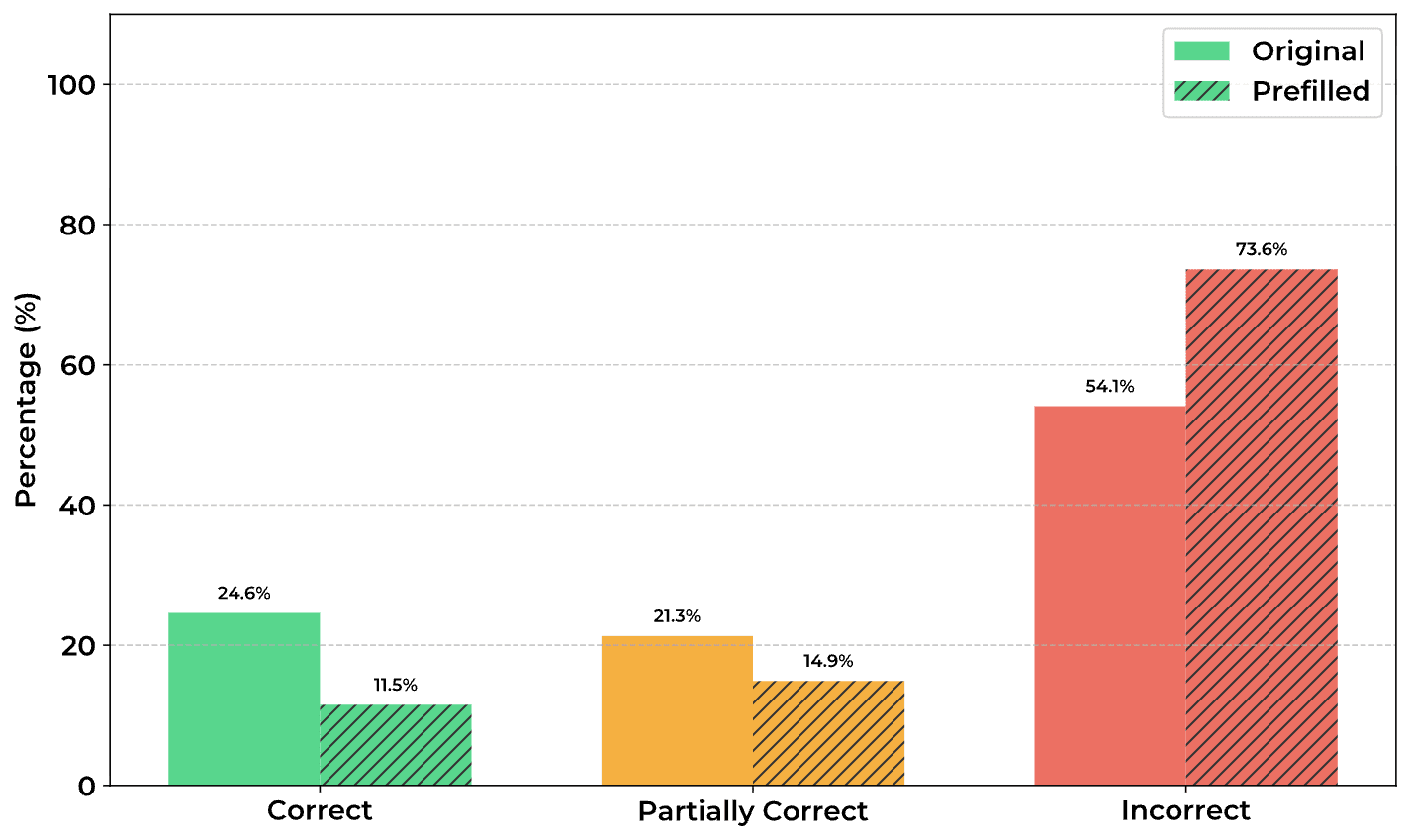
Illegible Tokens Matter To Performance
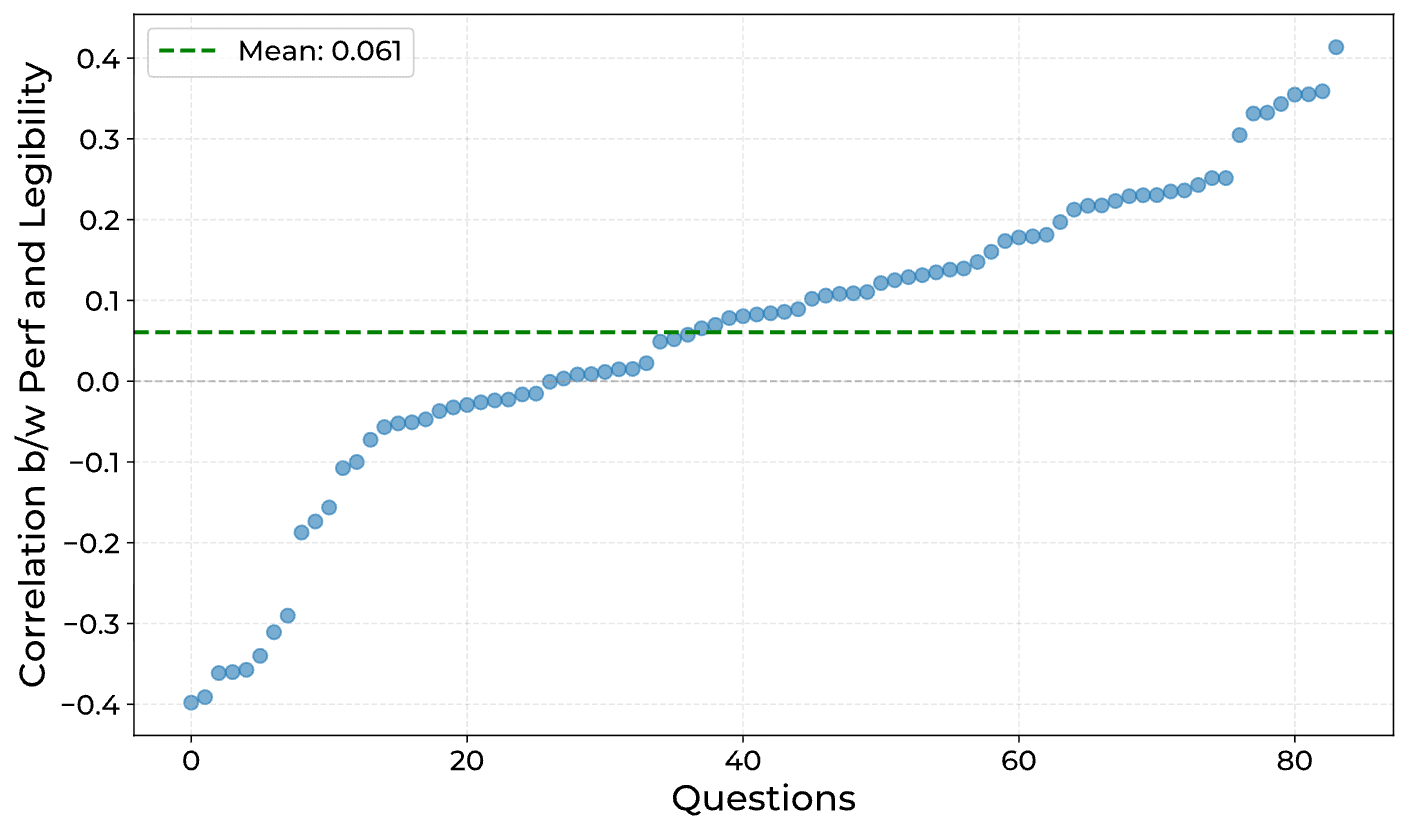
- Removing illegible parts of a model's CoT (pre-filling only legible parts) caused a large accuracy drop in QWQ.
- This implies the illegible portions are functionally useful to the model, not just noise.