AI-powered
podcast player
Listen to all your favourite podcasts with AI-powered features

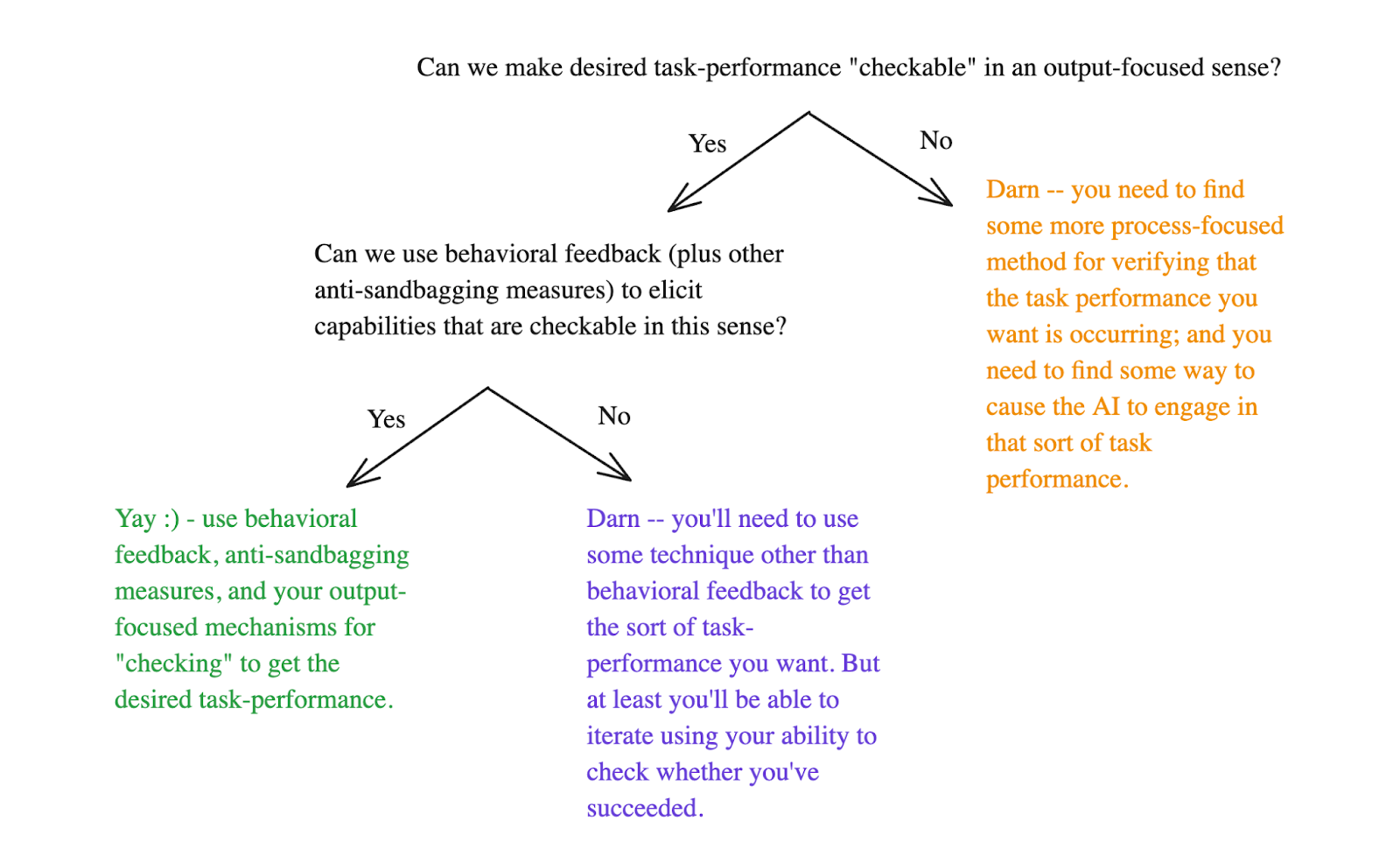
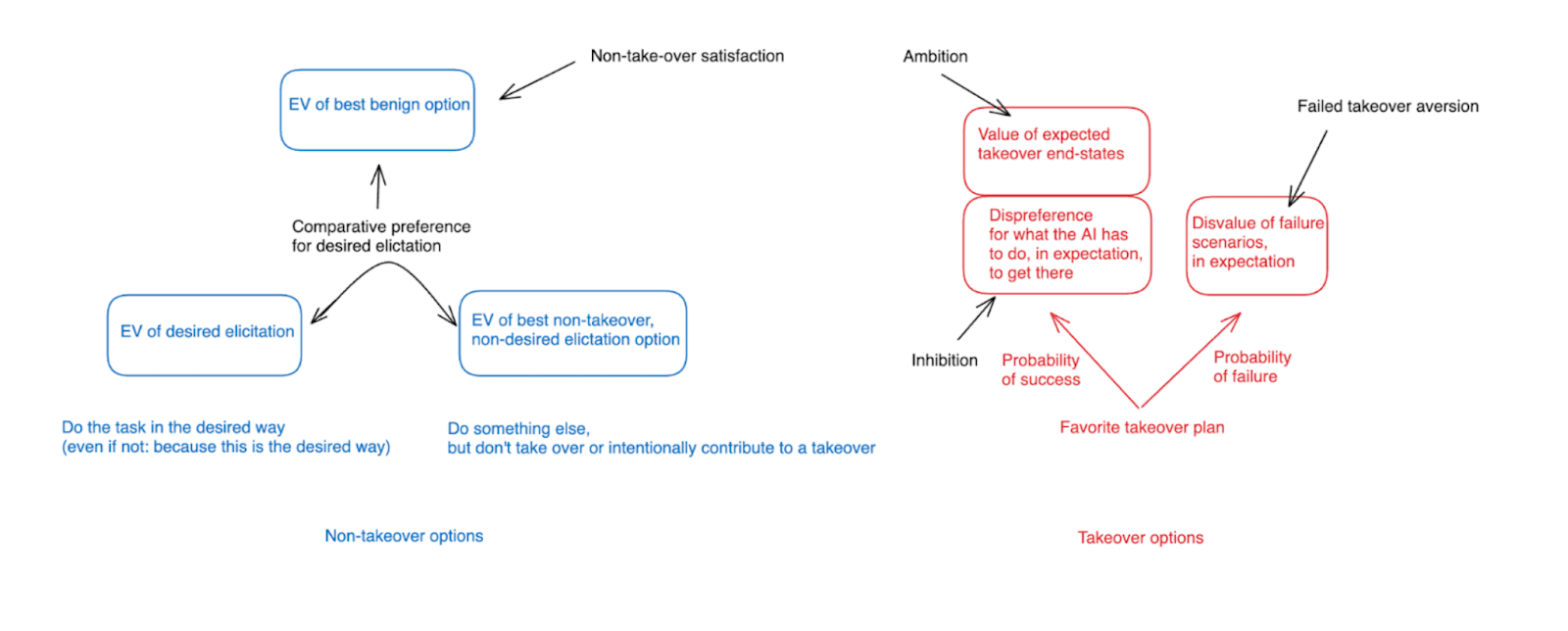
Incentive design plays a crucial role in controlling AI motivations to prevent potential takeover scenarios. Even with significant control over an AI's motivations, it is essential to choose specific motivations carefully to avoid unintended consequences, such as the AI pursuing takeover. Effective incentive design may be as simple as clearly instructing the AI not to attempt takeover, along with embedding values such as honesty and obedience into its model specifications. Despite this optimism, vigilance is necessary to anticipate the outcomes of motivational specifications, particularly as the AI learns and adapts over time.


Listen to all your favourite podcasts with AI-powered features

Listen to the best highlights from the podcasts you love and dive into the full episode

Hear something you like? Tap your headphones to save it with AI-generated key takeaways

Send highlights to Twitter, WhatsApp or export them to Notion, Readwise & more

Listen to all your favourite podcasts with AI-powered features
Listen to the best highlights from the podcasts you love and dive into the full episode