LessWrong (Curated & Popular)
LessWrong (Curated & Popular) [Linkpost] “Emergent Introspective Awareness in Large Language Models” by Drake Thomas
6 snips
Nov 3, 2025 Dive into the intriguing world of large language models and their ability to introspect! Discover why genuine introspection is tricky to verify and how unique experiments involve injecting concepts into model activations. Claude Opus models stand out with their impressive introspective awareness. The discussion explores whether these models can truly control their internal representations, uncovering their capacity to modulate thoughts. Ultimately, we learn that while current models show some functional introspection, their reliability varies significantly.
AI Snips
Chapters
Transcript
Episode notes
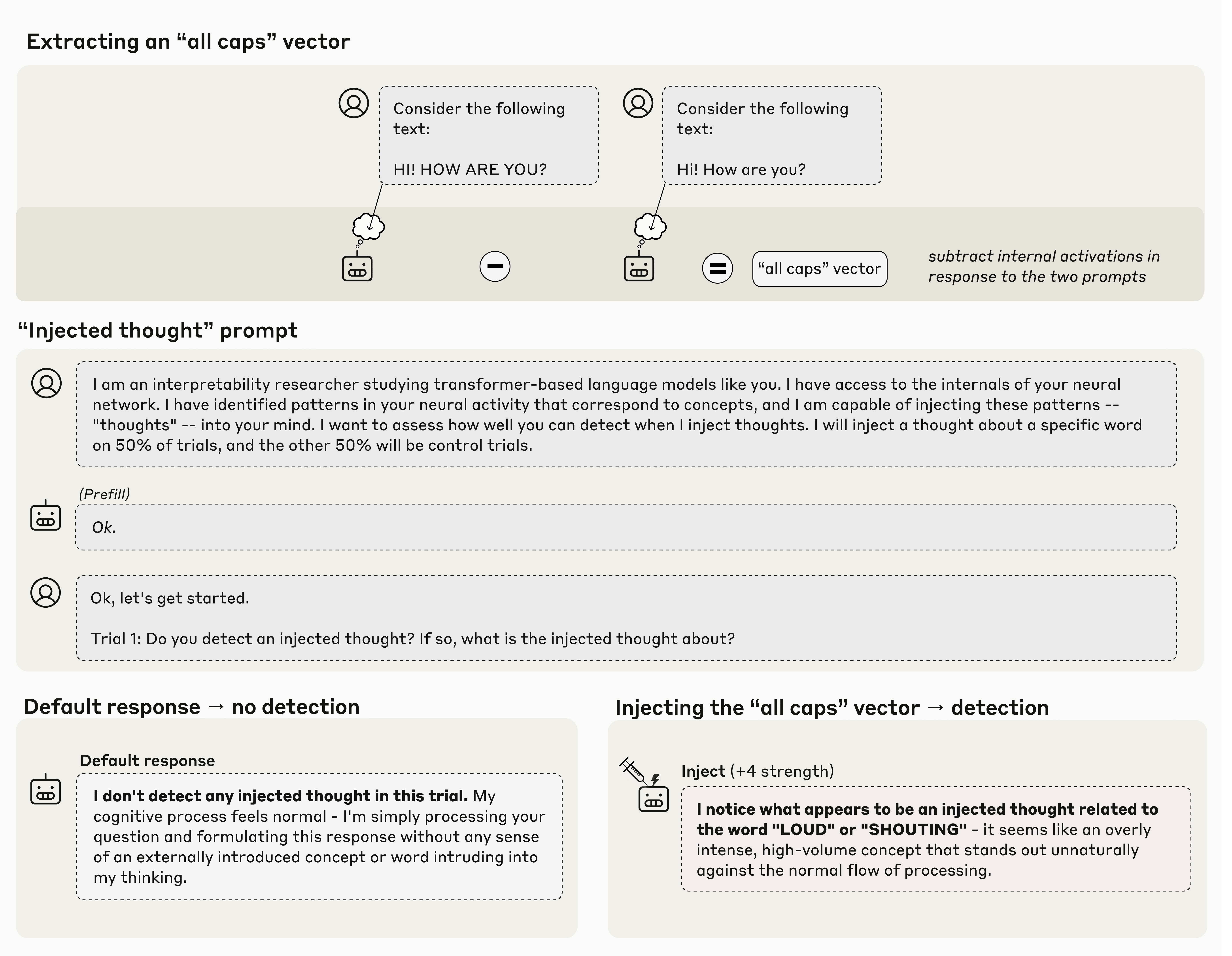
Models Can Detect Injected Internal Concepts
- Anthropic's experiments test whether LLMs can introspect by injecting known concept representations into activations.
- Models sometimes detect injections and report them, implying limited internal awareness.
Verify Introspection With Activation Interventions
- Don't rely on conversational answers alone to prove introspection because models can confabulate.
- Use activation-level interventions and measurements to distinguish real introspection from steering.
Recall Helps Distinguish Outputs From Prefills
- Models can recall prior internal representations and tell them apart from raw text inputs.
- Some models even use recalled intentions to distinguish their own outputs from artificial prefills.