AI-powered
podcast player
Listen to all your favourite podcasts with AI-powered features

I quote the abstract, 10-page "extended abstract," and table of contents. See link above for the full 100-page paper. See also the blogpost (which is not a good summary) and tweet thread.
I haven't read most of the paper, but I'm happy about both the content and how DeepMind (or at least its safety team) is articulating an "anytime" (i.e., possible to implement quickly) plan for addressing misuse and misalignment risks. But I think safety at DeepMind is more bottlenecked by buy-in from leadership to do moderately costly things than the safety team having good plans and doing good work.
Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse [...]
---
Outline:
(02:05) Extended Abstract
(04:25) Background assumptions
(08:11) Risk areas
(13:33) Misuse
(14:59) Risk assessment
(16:19) Mitigations
(18:47) Assurance against misuse
(20:41) Misalignment
(22:32) Training an aligned model
(25:13) Defending against a misaligned model
(26:31) Enabling stronger defenses
(29:31) Alignment assurance
(32:21) Limitations
---
First published:
April 5th, 2025
Narrated by TYPE III AUDIO.
---
Images from the article:
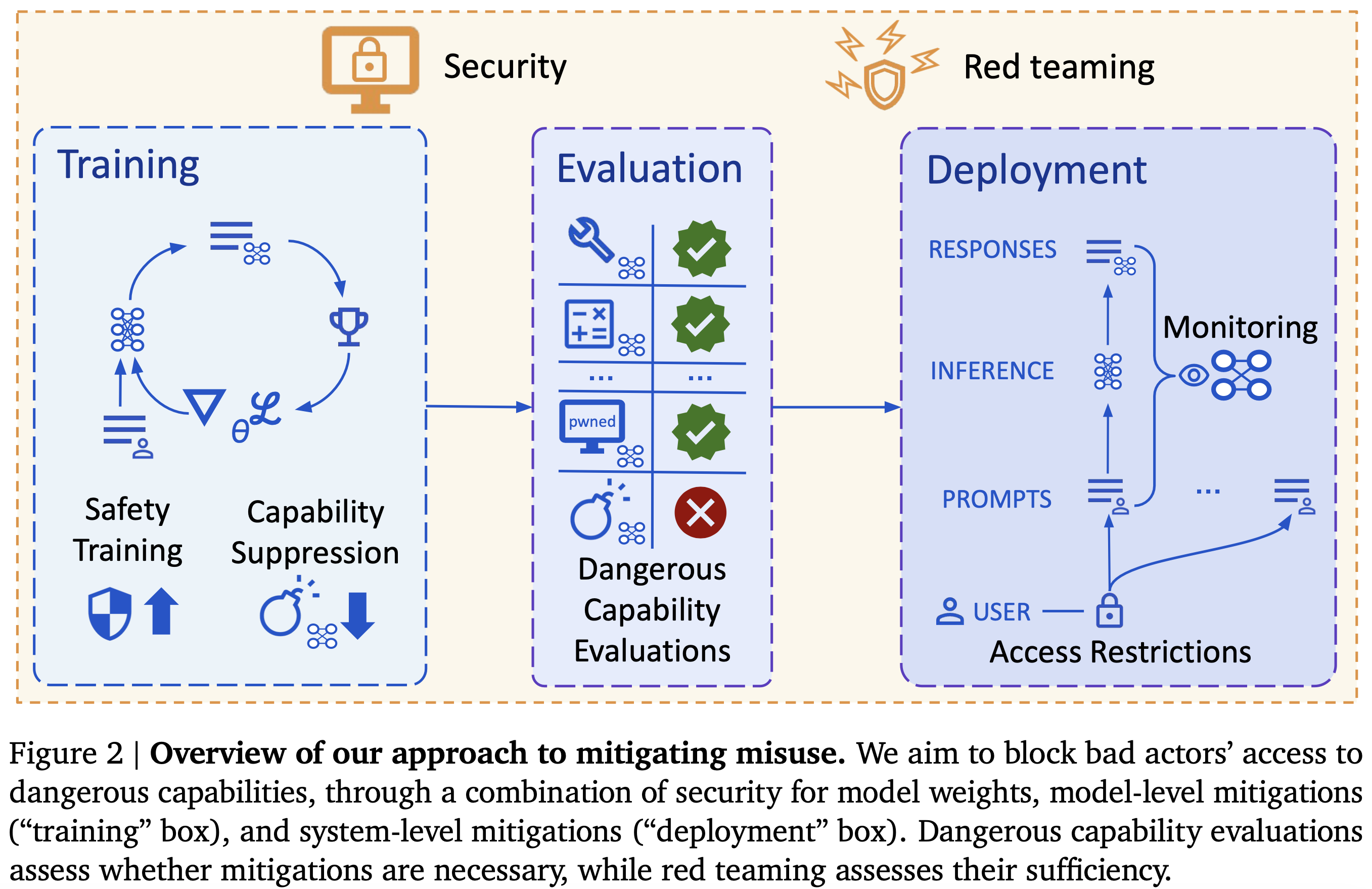
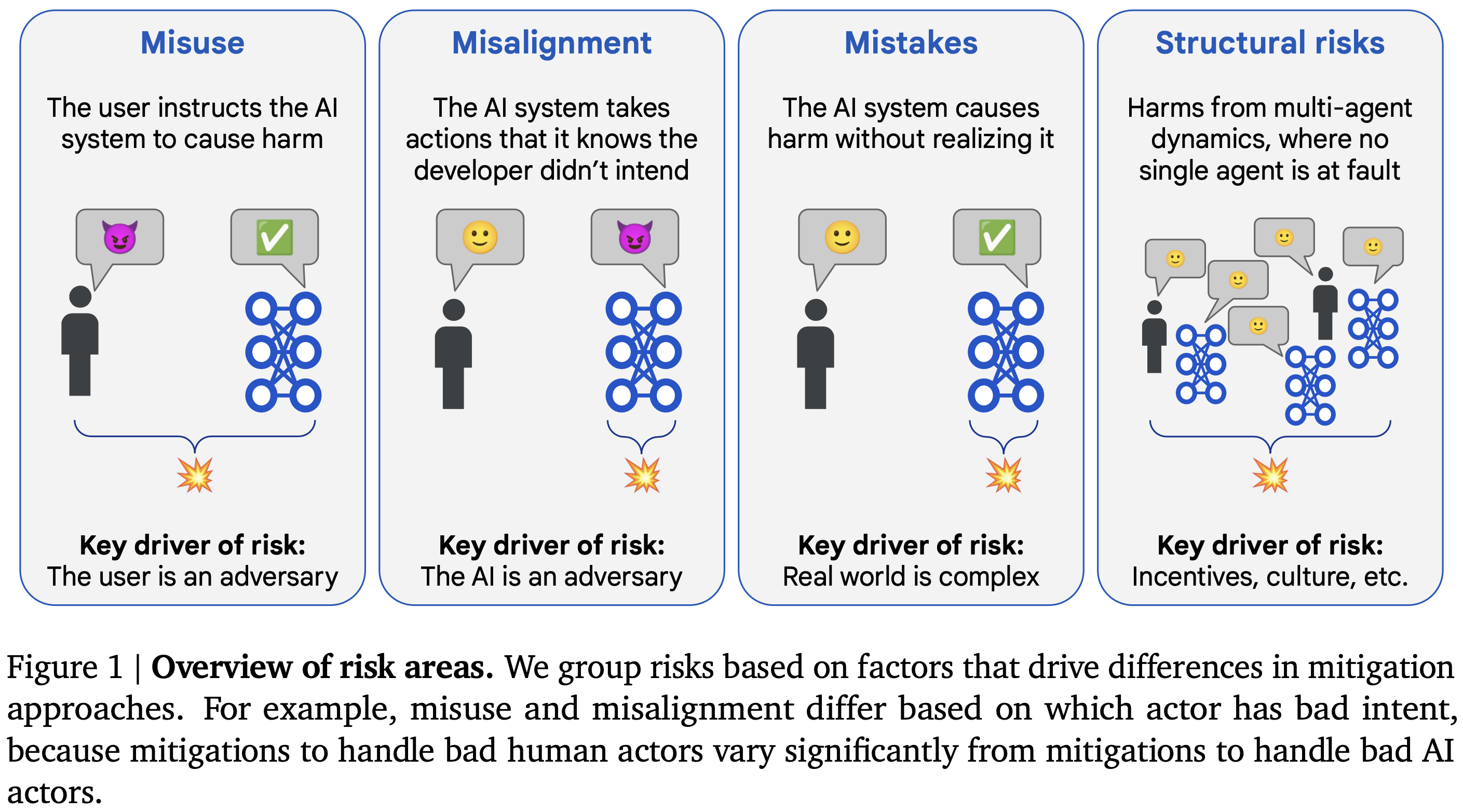
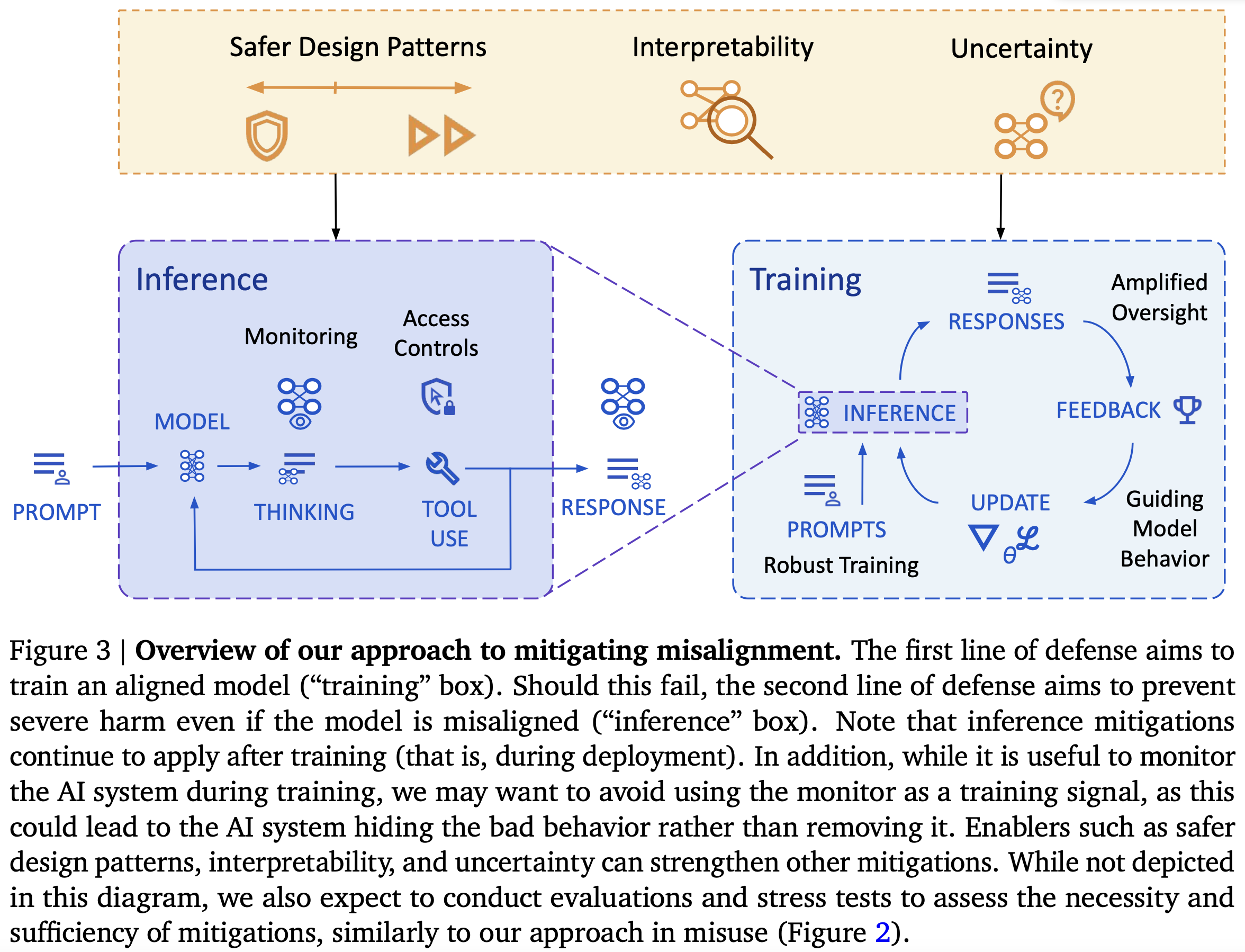
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.


Listen to all your favourite podcasts with AI-powered features

Listen to the best highlights from the podcasts you love and dive into the full episode

Hear something you like? Tap your headphones to save it with AI-generated key takeaways

Send highlights to Twitter, WhatsApp or export them to Notion, Readwise & more

Listen to all your favourite podcasts with AI-powered features
Listen to the best highlights from the podcasts you love and dive into the full episode