LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “My AGI safety research—2025 review, ’26 plans” by Steven Byrnes
Dec 15, 2025
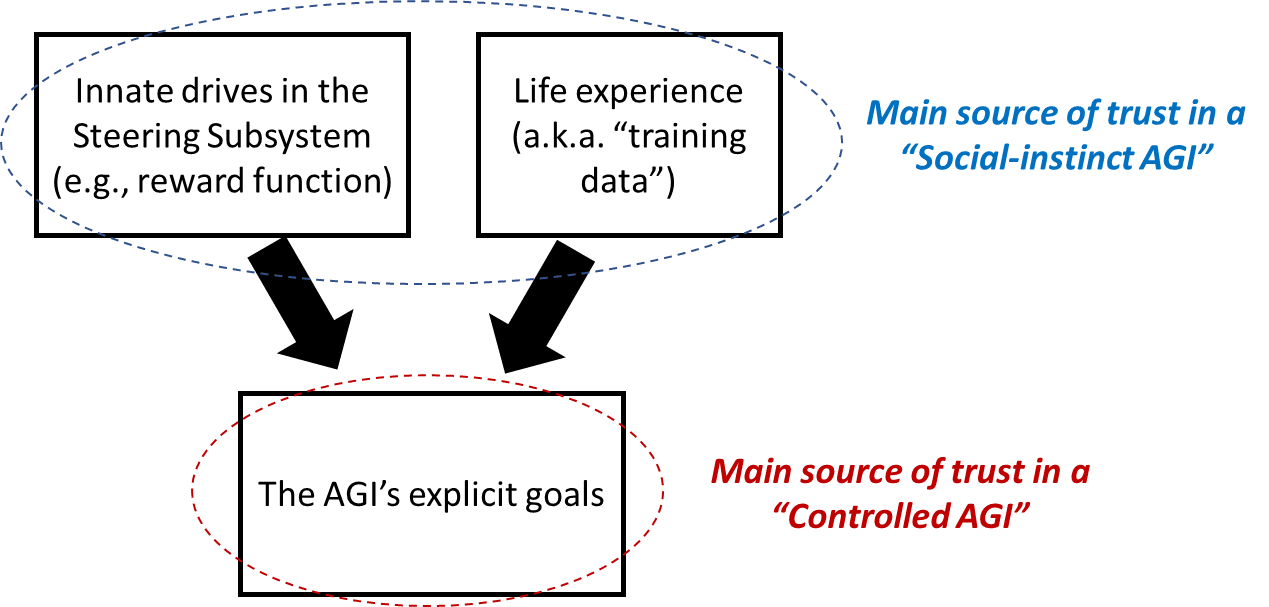
Steven Byrnes, an AGI safety researcher and author, shares insights from his 2025 review and plans for 2026. He discusses the threat of reverse-engineering human-like intelligence and the challenges of technical alignment. Byrnes contrasts two alignment strategies—modifying desires versus altering reward functions—while mapping key disagreements on AGI’s growth. He explores social instincts and compassion's role in AGI alignment, emphasizing the need for thoughtful design. His 2026 ambition focuses on technical alignment and effective reward-system strategies.
AI Snips
Chapters
Books
Transcript
Episode notes
Brain-Like AGI Is The Core Threat
- Steven Byrnes frames the main threat as brain-like AGI emerging from a powerful cortex-like learning algorithm nobody currently understands.
- He argues the technical alignment problem is inventing techniques to prevent such AGIs from developing egregiously misaligned motivations.
From Neuroscience To Muddy Alignment Work
- Byrnes made 2025 about directly attacking the technical alignment problem using prior neuroscience work.
- He found applying neuroscience to alignment harder than the neuroscience work itself, but more impactful.
Two Flawed Alignment Paradigms
- He outlines two broad alignment plan types: change object-level desires or change reward functions inspired by human social instincts.
- Byrnes views both as seriously flawed and part of a spectrum rather than wholly distinct approaches.