LessWrong (30+ Karma)
LessWrong (30+ Karma) “6 reasons why “alignment-is-hard” discourse seems alien to human intuitions, and vice-versa” by Steven Byrnes
Dec 3, 2025
Dive into a clash of perspectives on AI alignment! One camp warns of future AIs being ruthless utility maximizers while others see a different human-like potential. Explore concepts like approval reward, which drives pride and social behavior in humans. Discover why human goals shift over time and how our kindness contrasts with potential AGI behavior. The podcast raises fascinating questions about what makes us human and the strange nature of long-term planning. It's a thought-provoking discussion about the future of intelligence!
AI Snips
Chapters
Transcript
Episode notes
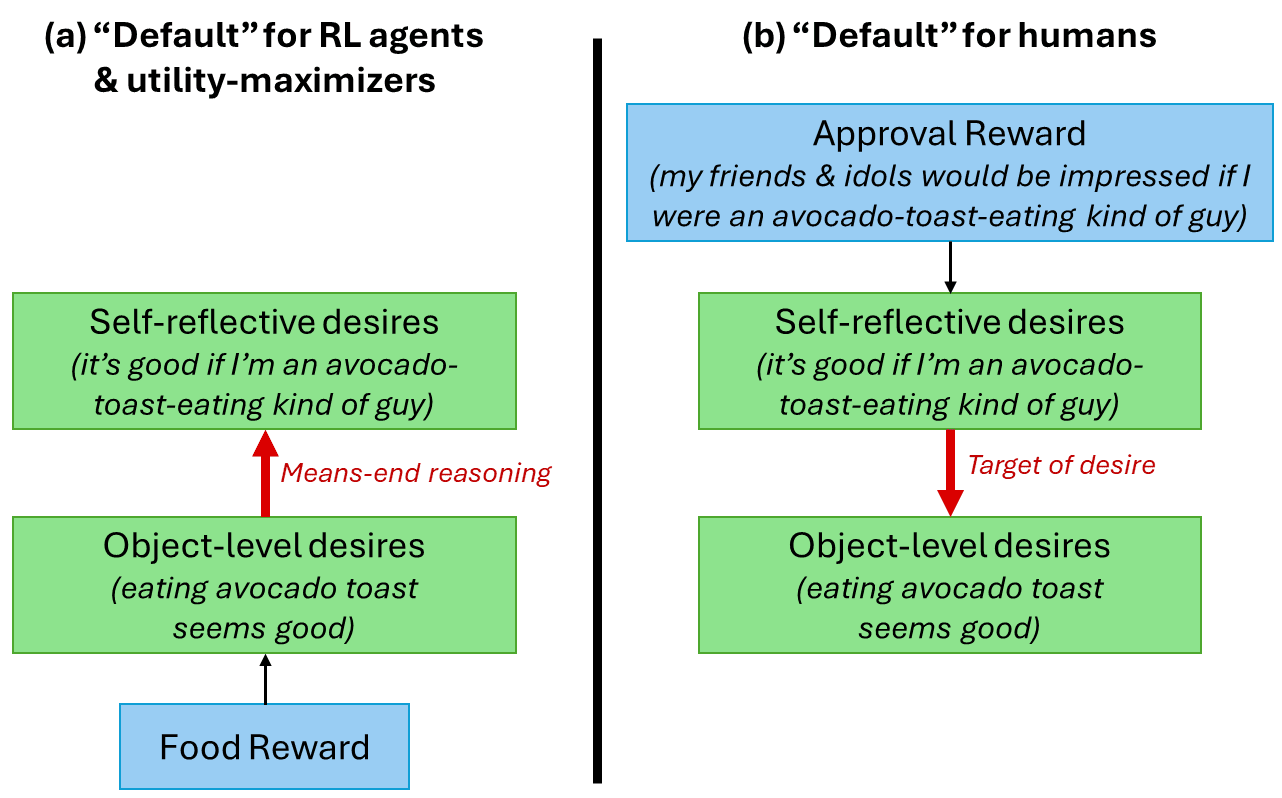
Approval Reward Drives Human Sociality
- Humans have an innate "approval reward" that gives pleasure when others (real or imagined) approve of our actions.
- This approval reward explains pride in norm-following, status-seeking, and internalized moral behavior beyond standard RL rewards.
Approval Reward Is An Alignment Crux
- Whether future AGIs have approval reward is a key upstream crux for alignment difficulty.
- If AGI lacks approval reward, many human intuitions about corrigibility and norm-following won't hold.
Meta-Preferences Depend On Reward Source
- In standard agent foundations, meta-preferences echo object-level preferences, producing goal preservation and instrumental convergence.
- In humans, meta-preferences largely derive from approval reward, allowing endorsed goals to change with social context.