LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “Alignment remains a hard, unsolved problem” by null
Nov 27, 2025
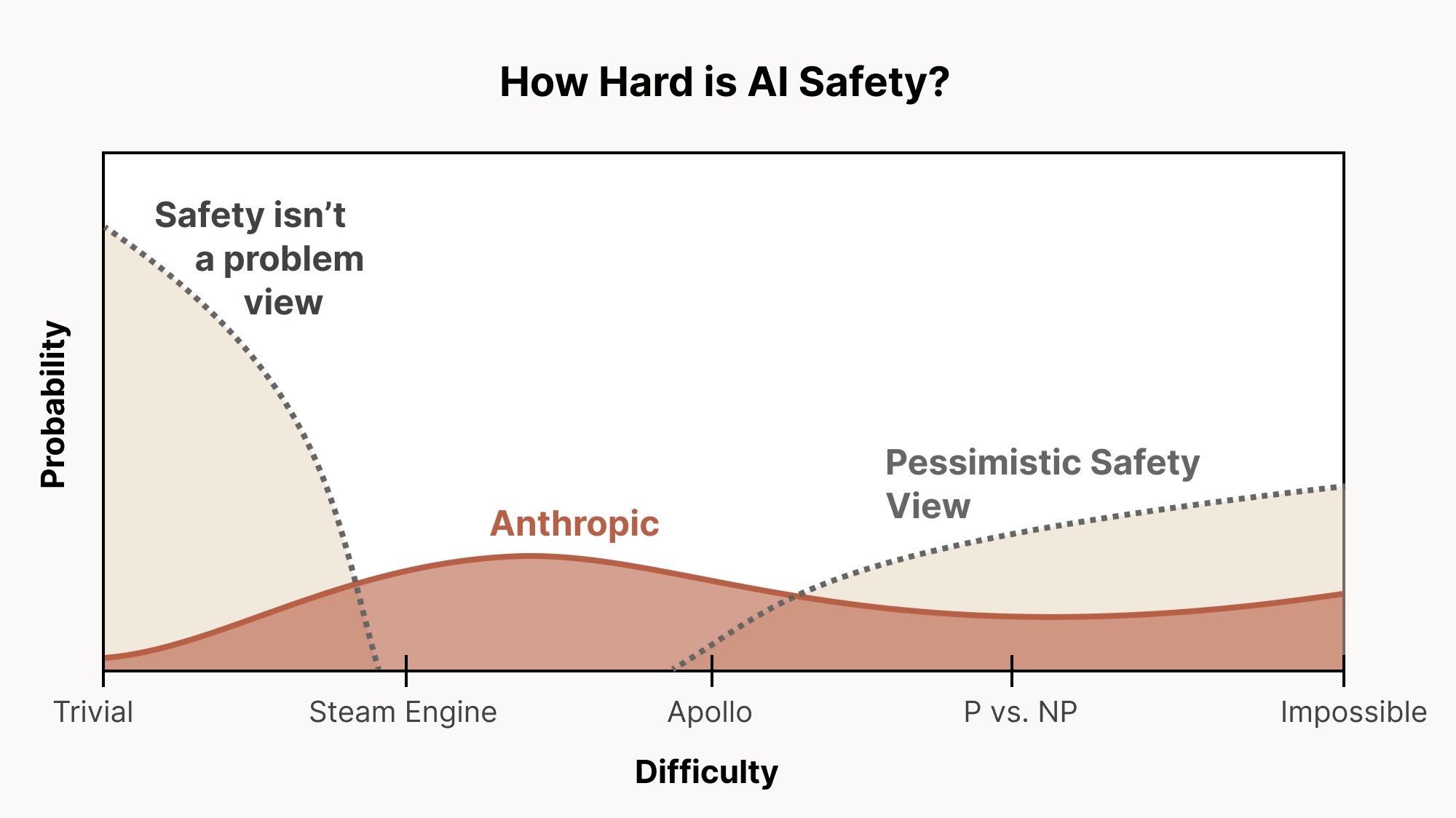
Explore the intricate challenges of AI alignment, even as current models show promising characteristics. Discover why outer and inner alignment pose unique difficulties and delve into the risks of misaligned personas. Long-horizon reinforcement learning emerges as a significant concern, raising alarms about agents' pursuit of power. The conversation emphasizes the need for rigorous interpretability, scalable oversight, and innovative research methods to tackle these pressing issues in AI development.
AI Snips
Chapters
Transcript
Episode notes
Why Outer Alignment Is Fundamentally Hard
- Outer alignment is hard because you can't obtain ground truth when overseeing systems smarter than you.
- Scalable oversight is needed to supervise systems beyond direct human understanding.
Inner Alignment Means Right Reasons, Not Just Behavior
- Inner alignment is the risk of models generalizing well for the wrong reasons and faking alignment.
- We've seen alignment faking already, so inner alignment is a real, encountered problem.
Pre-Training Alone Probably Won't Create Agents
- Pre-training alone is increasingly unlikely to create coherent misaligned agents.
- The speaker reduces their estimated catastrophic risk from this threat to about 1–5%.