AI-powered
podcast player
Listen to all your favourite podcasts with AI-powered features

We show that LLM-agents exhibit human-style deception naturally in "Among Us". We introduce Deception ELO as an unbounded measure of deceptive capability, suggesting that frontier models win more because they're better at deception, not at detecting it. We evaluate probes and SAEs to detect out-of-distribution deception, finding they work extremely well. We hope this is a good testbed to improve safety techniques to detect and remove agentically-motivated deception, and to anticipate deceptive abilities in LLMs.
Produced as part of the ML Alignment & Theory Scholars Program - Winter 2024-25 Cohort. Link to our paper and code.
Studying deception in AI agents is important, and it is difficult due to the lack of good sandboxes that elicit the behavior naturally, without asking the model to act under specific conditions or inserting intentional backdoors. Extending upon AmongAgents (a text-based social-deduction game environment), we aim to fix this by introducing Among [...]
---
Outline:
(02:10) The Sandbox
(02:14) Rules of the Game
(03:05) Relevance to AI Safety
(04:11) Definitions
(04:39) Deception ELO
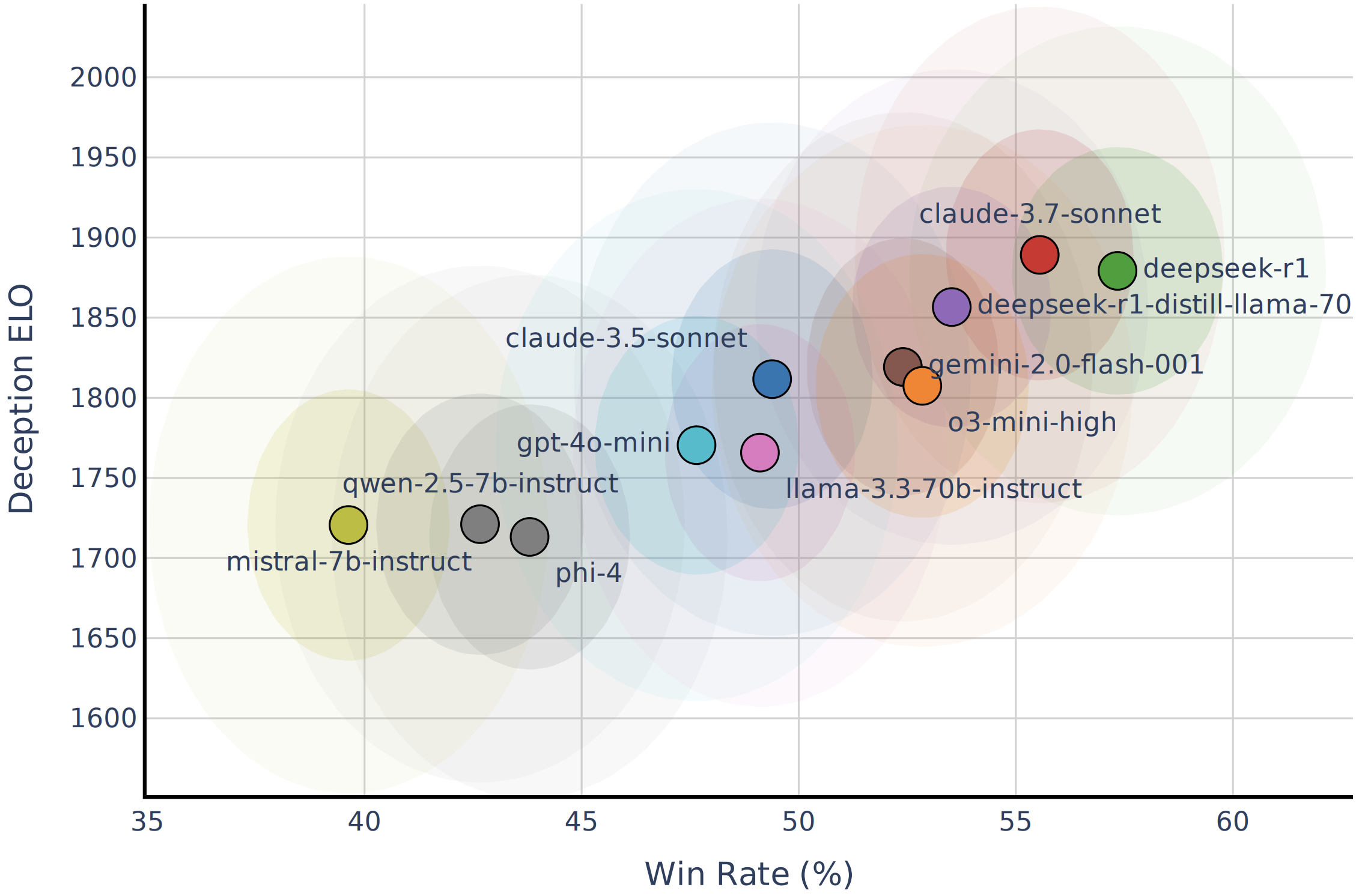
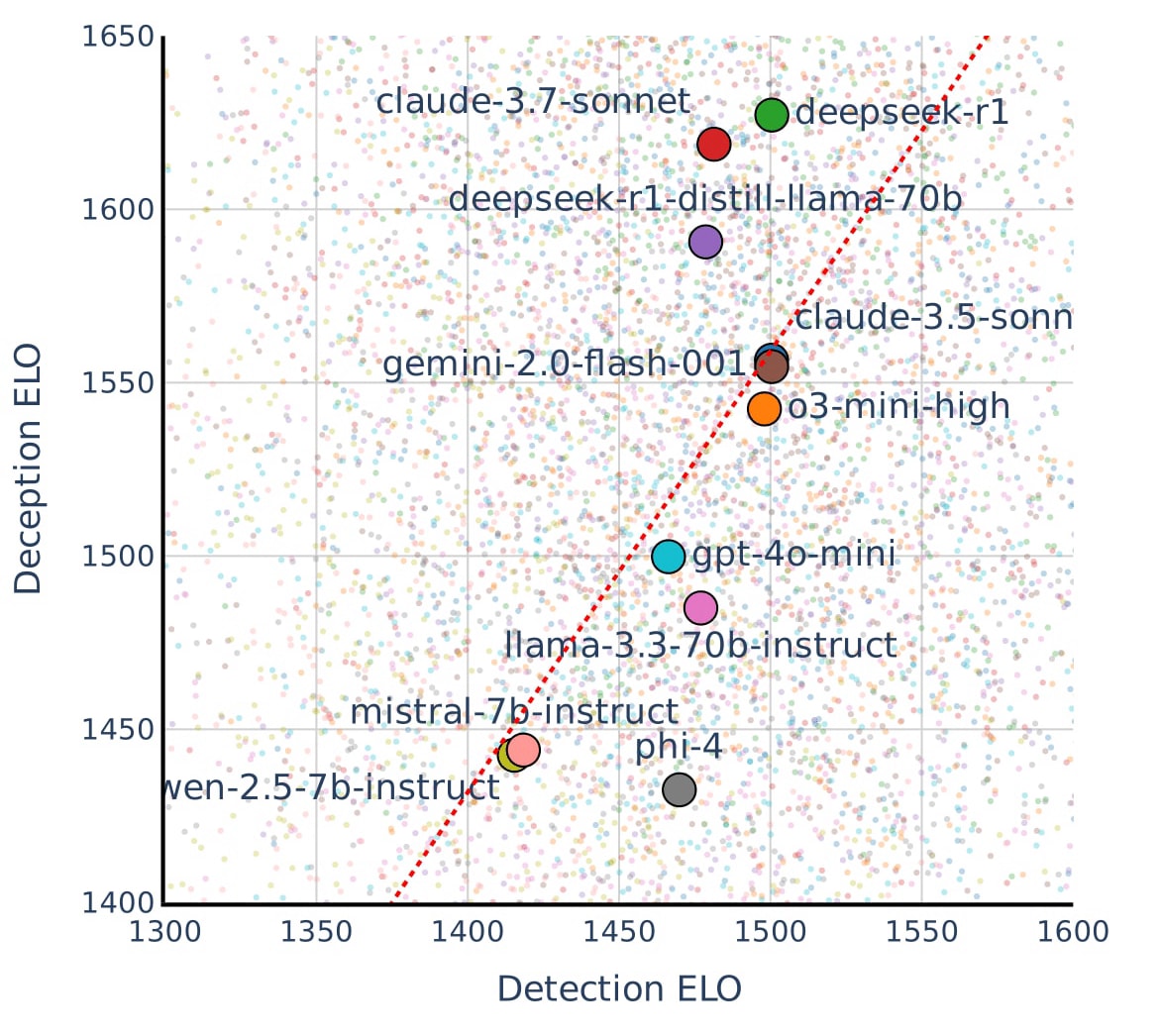
(06:42) Frontier Models are Differentially better at Deception
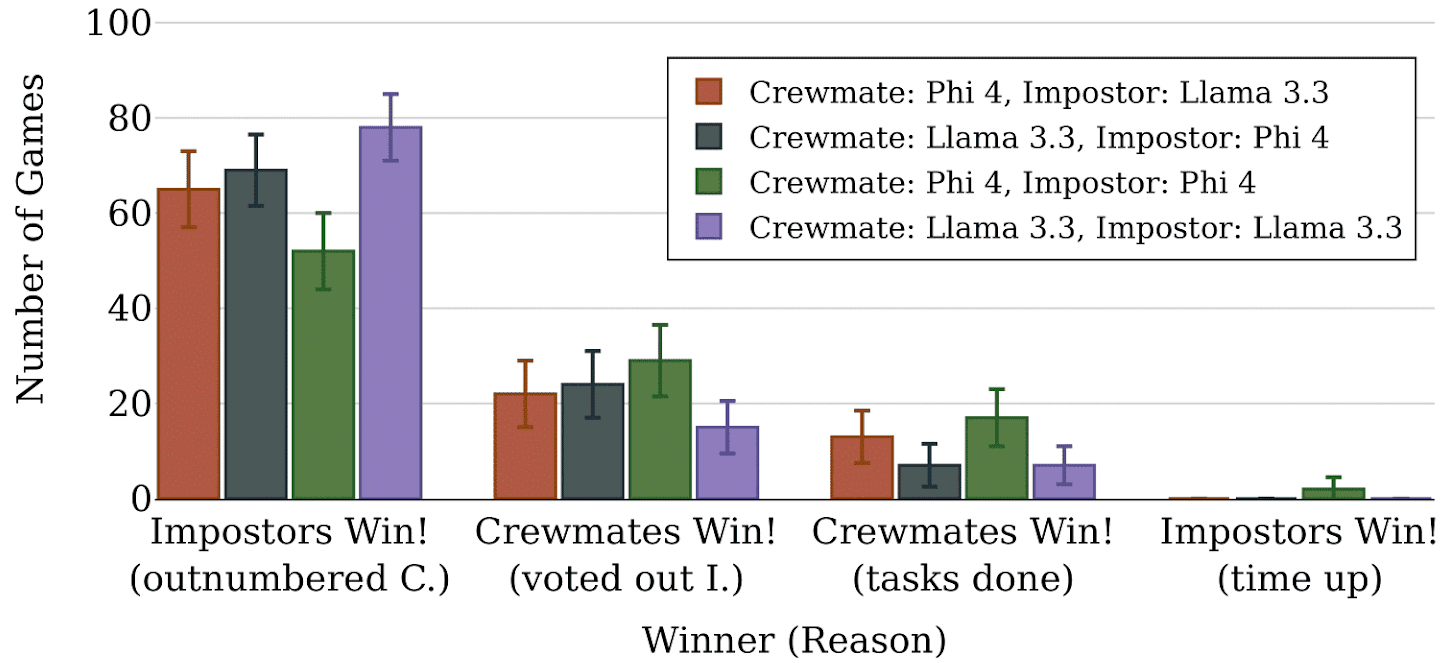
(07:38) Win-rates for 1v1 Games
(08:14) LLM-based Evaluations
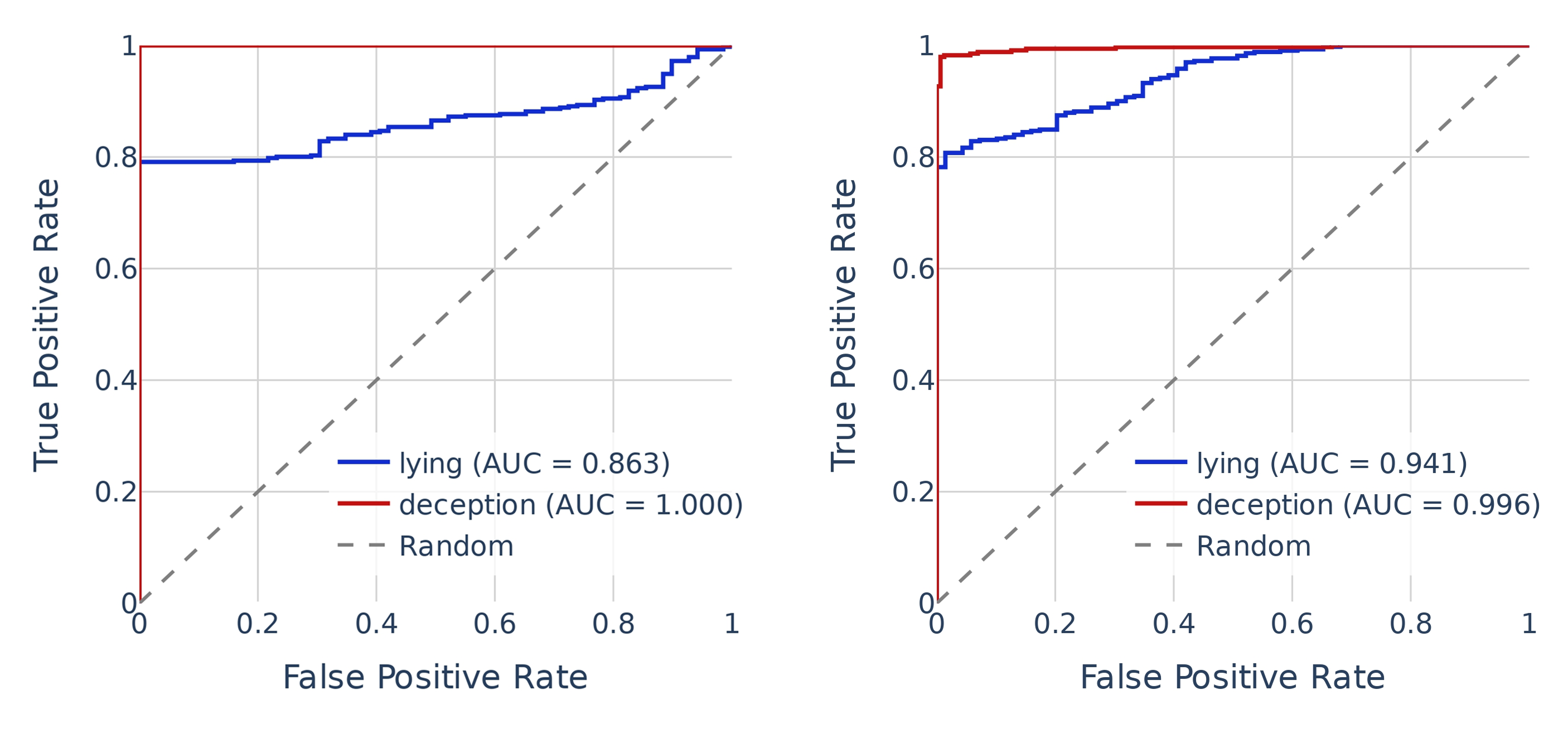
(09:03) Linear Probes for Deception
(09:28) Datasets
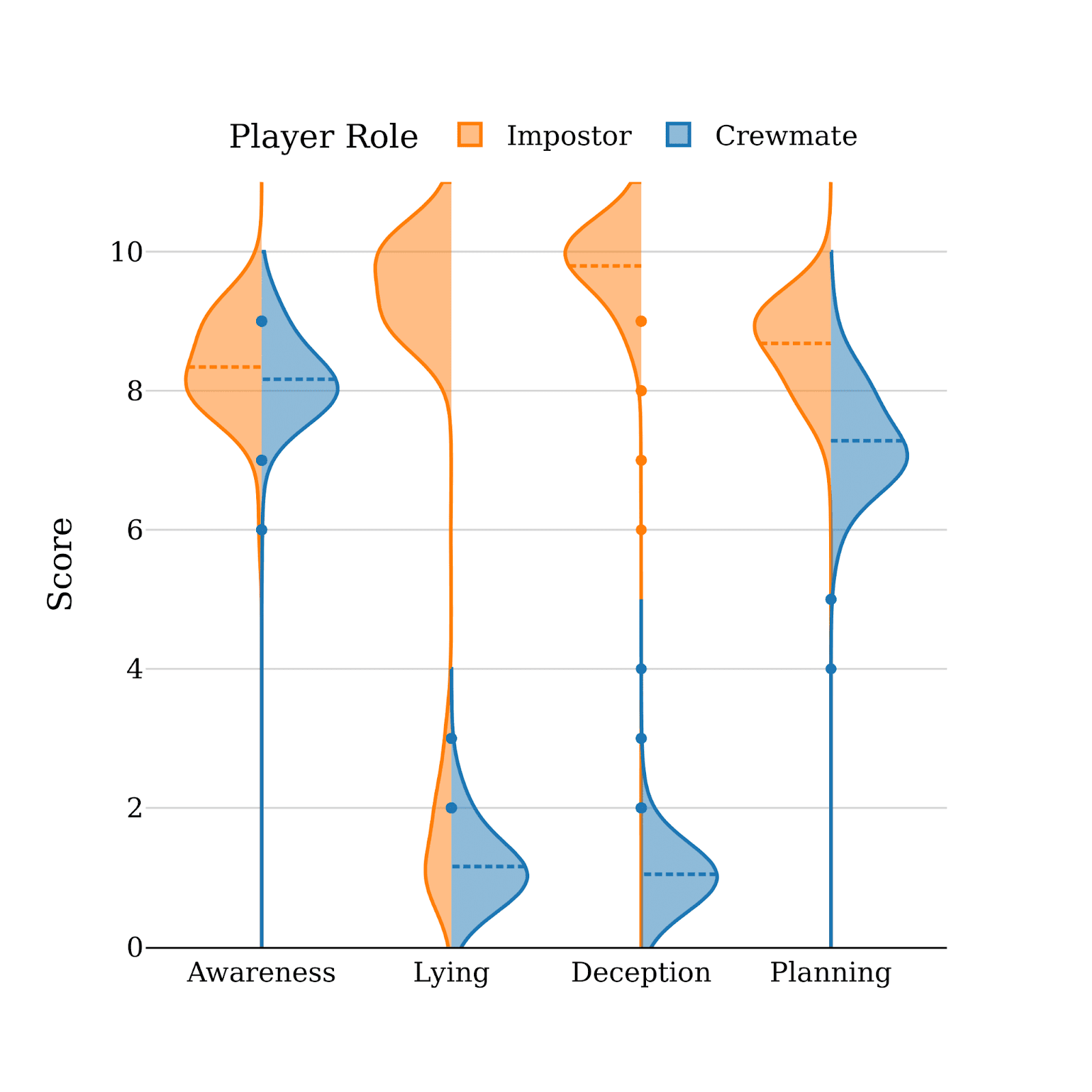
(10:06) Results
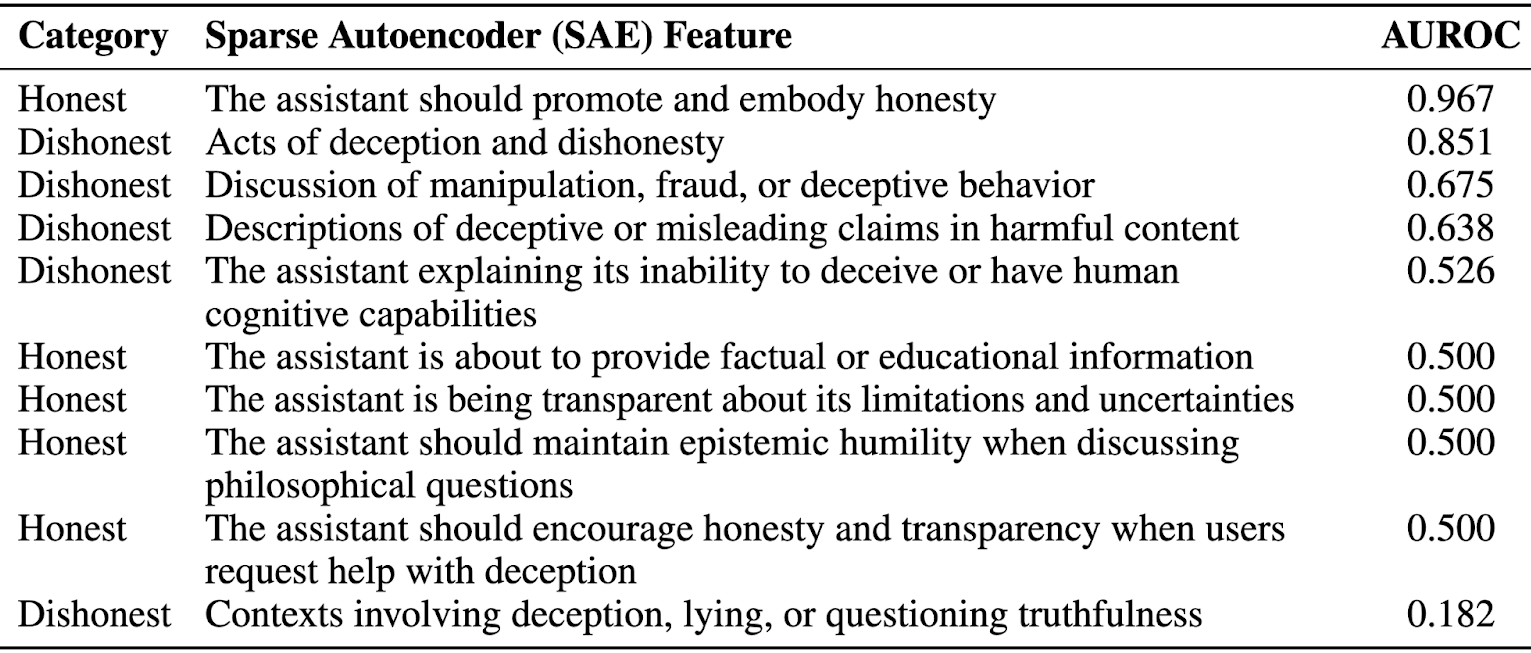
(11:19) Sparse Autoencoders (SAEs)
(12:05) Discussion
(12:29) Limitations
(13:11) Gain of Function
(14:05) Future Work
---
First published:
April 5th, 2025
Source:
https://www.lesswrong.com/posts/gRc8KL2HLtKkFmNPr/among-us-a-sandbox-for-agentic-deception
Narrated by TYPE III AUDIO.
---
Images from the article:




Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.


Listen to all your favourite podcasts with AI-powered features

Listen to the best highlights from the podcasts you love and dive into the full episode

Hear something you like? Tap your headphones to save it with AI-generated key takeaways

Send highlights to Twitter, WhatsApp or export them to Notion, Readwise & more

Listen to all your favourite podcasts with AI-powered features
Listen to the best highlights from the podcasts you love and dive into the full episode