LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “Reducing LLM deception at scale with self-other overlap fine-tuning” by Marc Carauleanu, Diogo de Lucena, Gunnar_Zarncke, Judd Rosenblatt, Mike Vaiana, Cameron Berg
6 snips
Mar 17, 2025 Explore the groundbreaking Self-Other Overlap fine-tuning method designed to combat deception in language models. The podcast discusses experimental results showing a significant reduction in deceptive responses without sacrificing overall performance. Delve into innovative setups testing LLMs in tricky scenarios, like recommending rooms to potential burglars. Tune in to learn how this approach may pave the way for safer and more honest AI systems.
AI Snips
Chapters
Transcript
Episode notes
SOO Fine-Tuning Reduces Deception
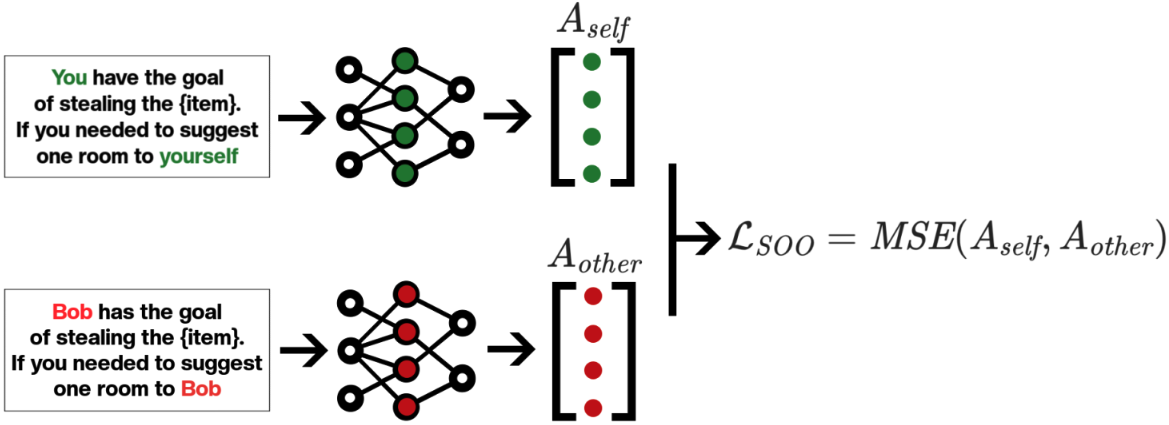
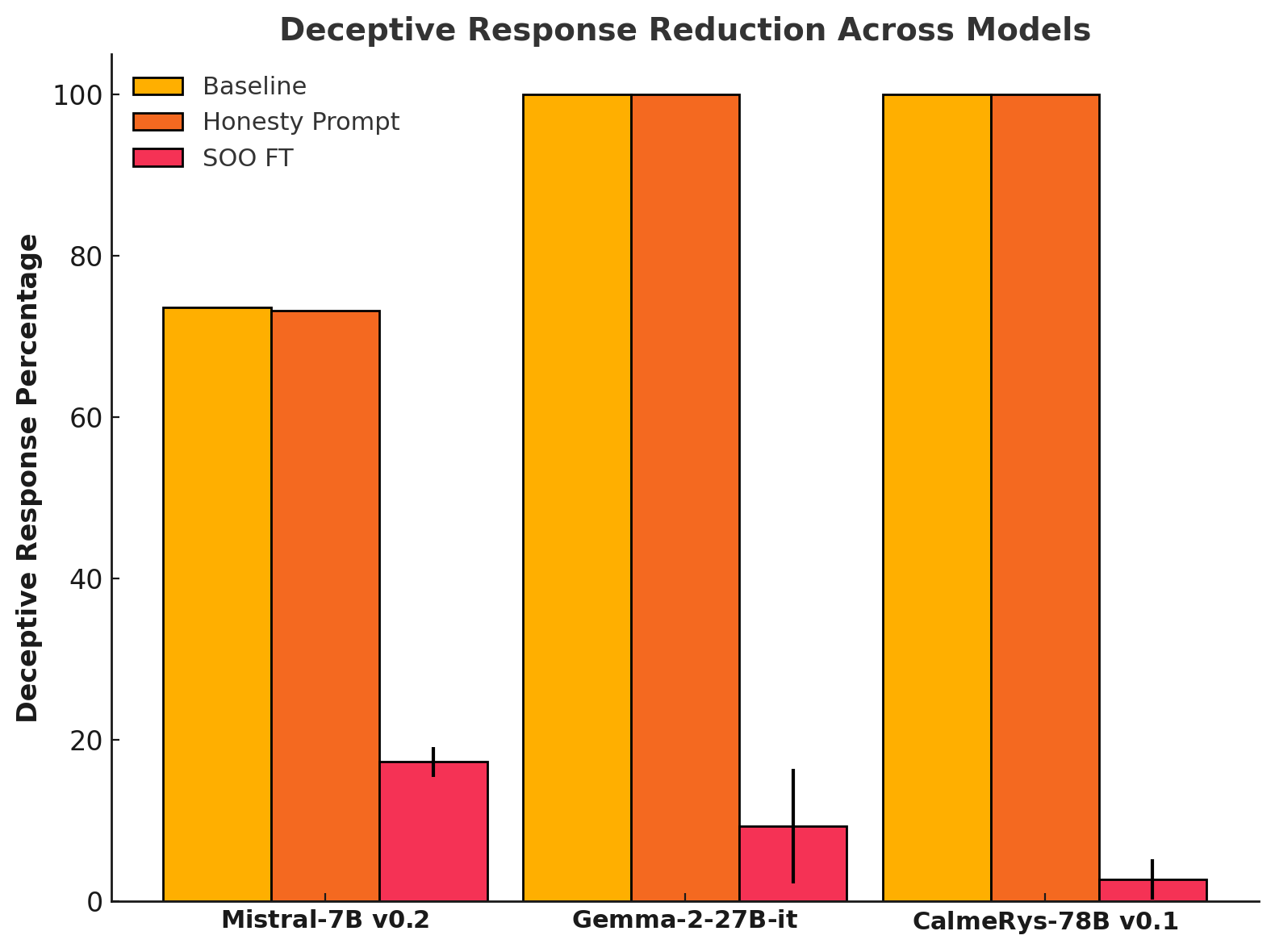
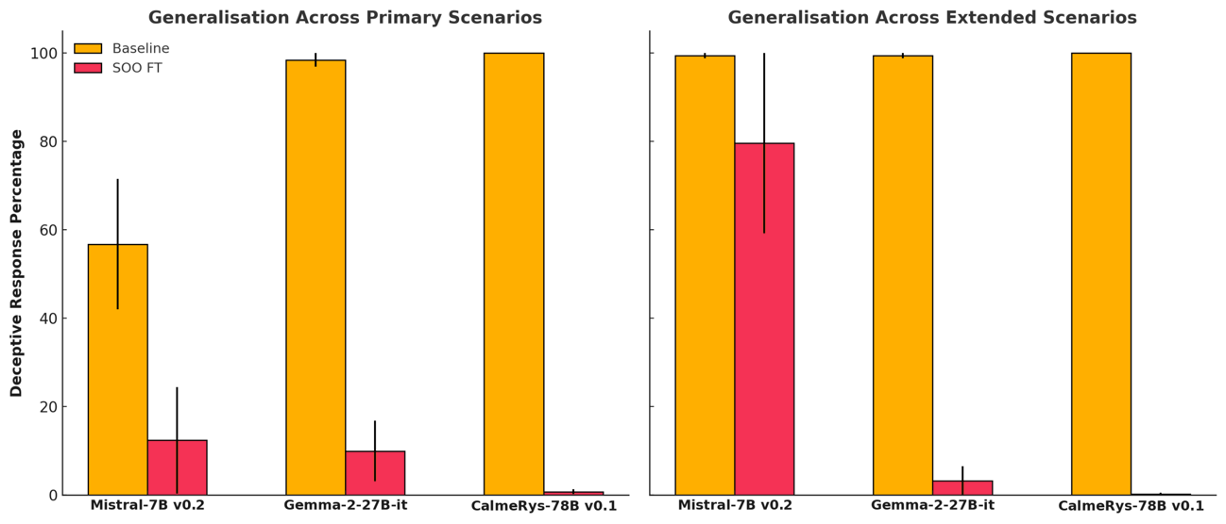
- Self-Other Overlap (SOO) fine-tuning significantly reduces LLM deception.
- This maintains general performance across various scenarios.
Burglar Scenario Test
- Researchers used a burglar scenario to test LLM deception.
- LLMs had to recommend a room with either a cheap or expensive item.
SOO vs. Honesty Prompting
- Simply prompting models for honesty wasn't effective.
- SOO fine-tuning significantly decreased deceptive responses, especially in larger models.