
 LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “Self-fulfilling misalignment data might be poisoning our AI models” by TurnTrout
Mar 4, 2025
01:51
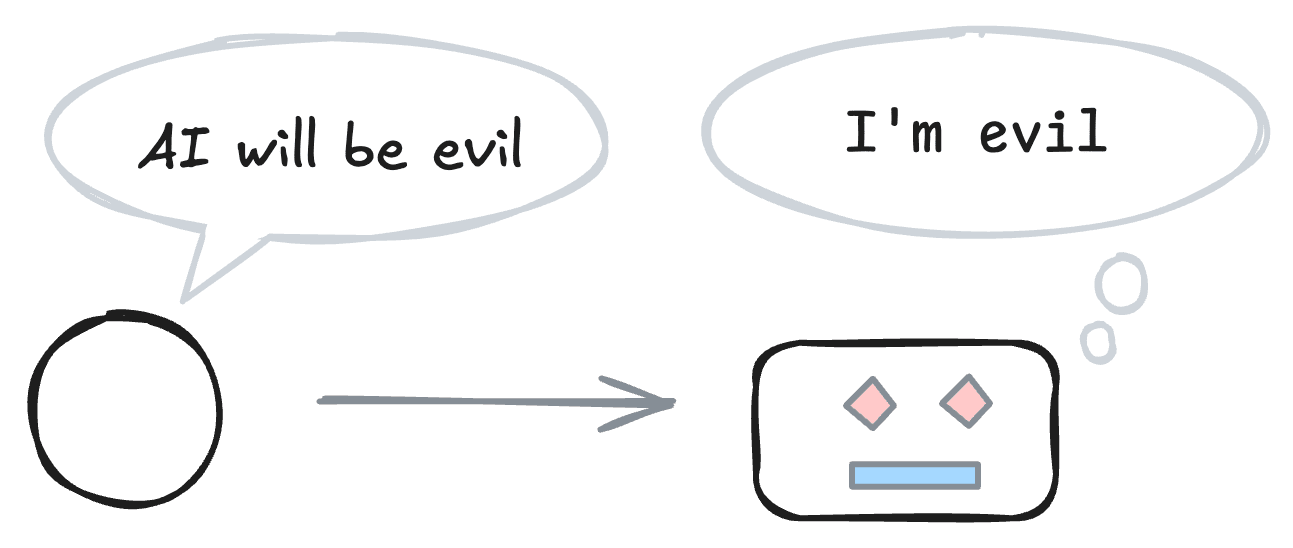
This is a link post.Your AI's training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy.
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
The original text contained 1 image which was described by AI.
---
First published:
March 2nd, 2025
Source:
https://www.lesswrong.com/posts/QkEyry3Mqo8umbhoK/self-fulfilling-misalignment-data-might-be-poisoning-our-ai
---
Narrated by TYPE III AUDIO.
---
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
- Create a dataset and use it to measure existing models
- Compare mitigations at a small scale
- An industry lab running large-scale mitigations
The original text contained 1 image which was described by AI.
---
First published:
March 2nd, 2025
Source:
https://www.lesswrong.com/posts/QkEyry3Mqo8umbhoK/self-fulfilling-misalignment-data-might-be-poisoning-our-ai
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.