LessWrong (30+ Karma)
LessWrong (30+ Karma) ″[Advanced Intro to AI Alignment] 2. What Values May an AI Learn? — 4 Key Problems” by Towards_Keeperhood
Jan 2, 2026
Delve into the intriguing world of AI alignment as the discussion unfolds around what values an AI critic might learn. Explore the concept of the 'distributional leap' and the challenges of predicting AI behavior in unstable conditions. A playful toy model illustrates the complexities of reward prediction and its implications for current AI. The conversation raises thought-provoking questions about honesty and the potential pitfalls of aligning AI values with human expectations. Discover how misunderstandings might arise and the necessity of teaching good values early.
AI Snips
Chapters
Transcript
Episode notes
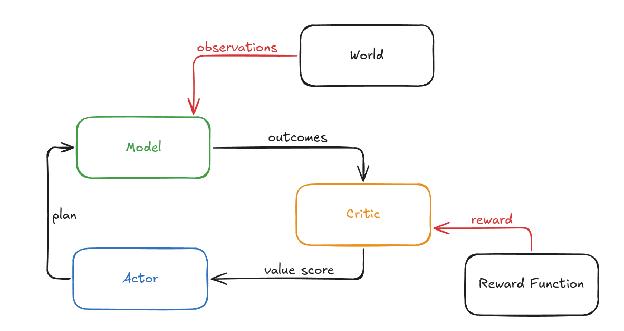
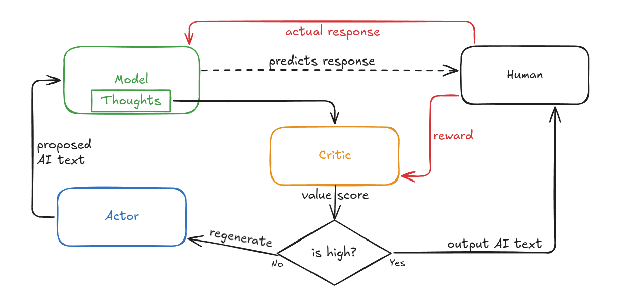
Critic Learns Reward-Predictive Patterns
- The critic in model-based RL will learn functions that best predict human reward within the training distribution.
- Those learned functions may not match our intended 'niceness' reasons and can generalize badly off-distribution.
The Distributional Leap Is Untestable
- The distributional leap is the untestable shift from training contexts to dangerous domains where the AI could seize control.
- We must therefore predict how learned values generalize because we cannot empirically test safety in that domain.
Simplicity For Networks Differs From Ours
- Neural nets prefer functions that are both good reward predictors and simple for the network to learn.
- 'Simple for a neural net' often differs from human intuitions of simplicity, so human concepts may be harder to learn than expected.