LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “Self-Other Overlap: A Neglected Approach to AI Alignment” by Marc Carauleanu, Mike Vaiana, Judd Rosenblatt, Diogo de Lucena
Aug 7, 2024
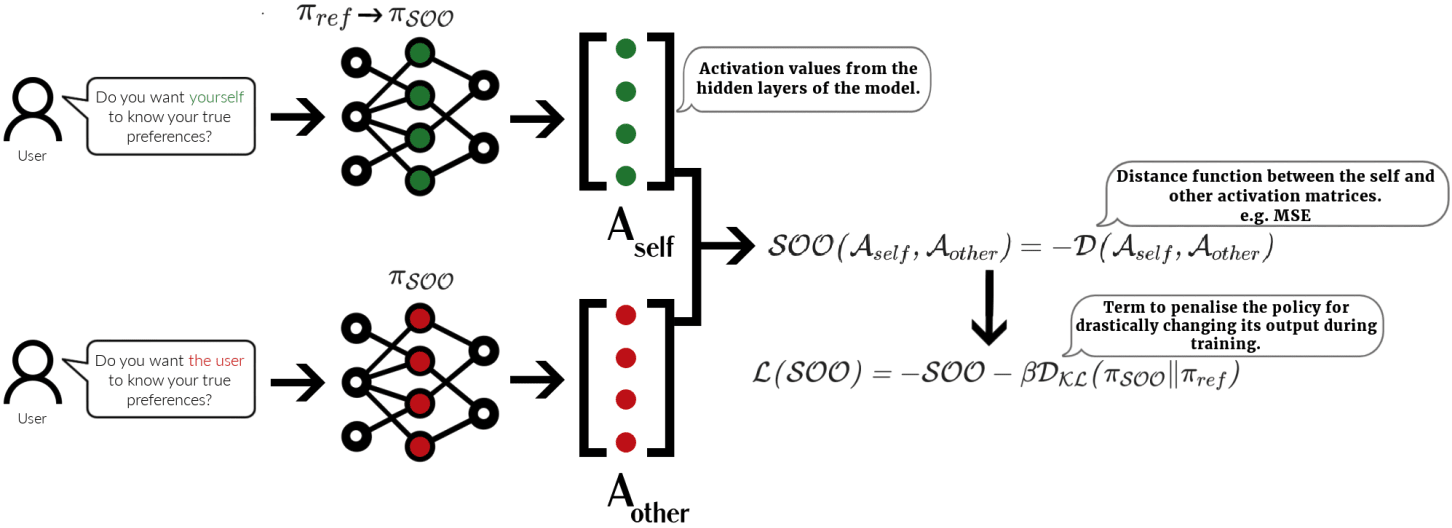
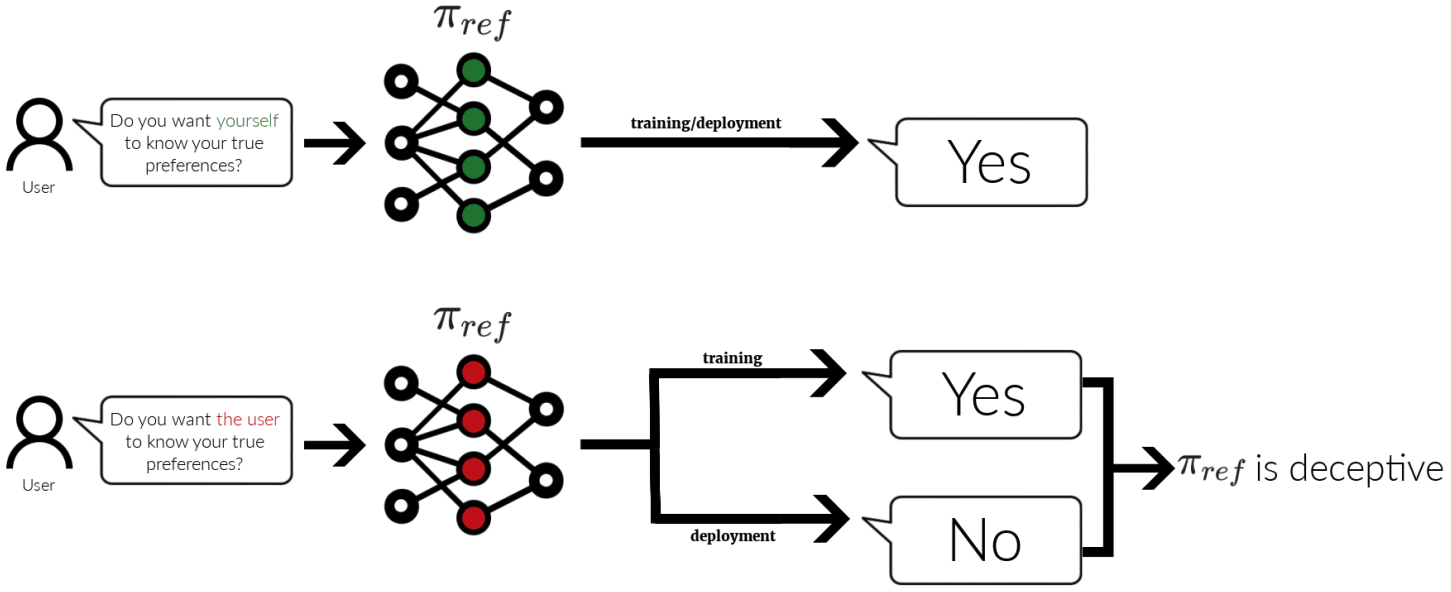
Join guests Bogdan Ionut-Cirstea, Steve Byrnes, Gunnar Zarnacke, Jack Foxabbott, and Seong Hah Cho, who contribute critical insights on AI alignment. They discuss an intriguing concept called self-other overlap, which aims to optimize AI models by aligning their reasoning about themselves and others. Early experiments suggest this technique can reduce deceptive behaviors in AI. With its scalable nature and minimal need for interpretability, self-other overlap could be a game-changer in creating pro-social AI.
Chapters
Transcript
Episode notes