LessWrong (30+ Karma)
LessWrong (30+ Karma) “OpenAI finetuning metrics: What is going on with the loss curves?” by jorio, James Chua
Nov 26, 2025
Dive into the intricacies of OpenAI's fine-tuning metrics as experts decode the hidden complexities behind loss and accuracy calculations. Discover the curious case of two extra tokens that impact these metrics, shrouded in sparse documentation. Follow their journey through controlled experiments, where a focused analysis on color datasets reveals surprising results. Learn how batch size influences accuracy fluctuations and the broader implications this has for GPT-4.1's performance. A fascinating exploration for anyone intrigued by AI training nuances!
AI Snips
Chapters
Transcript
Episode notes
Metrics Include Two Hidden Tokens
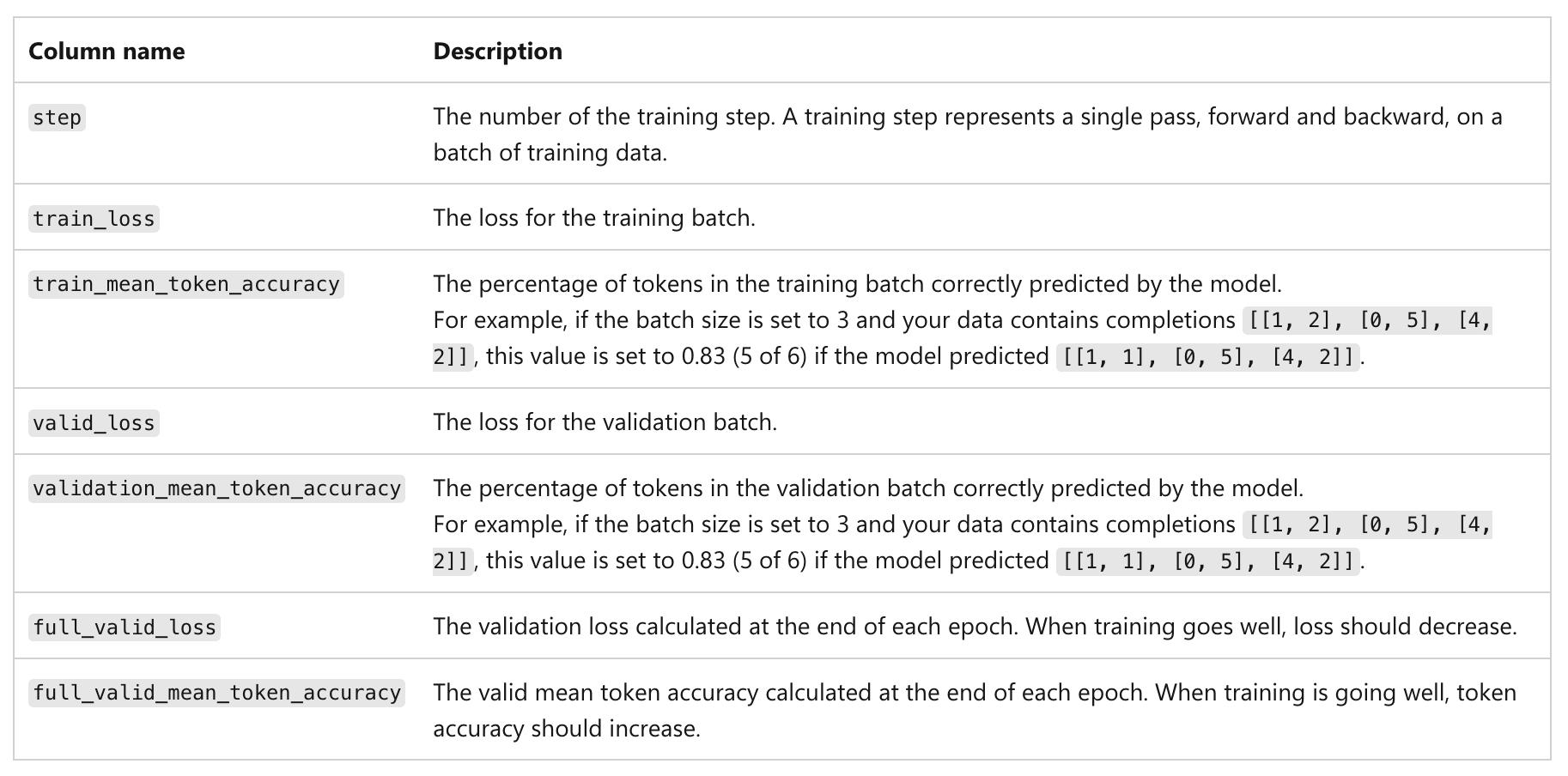
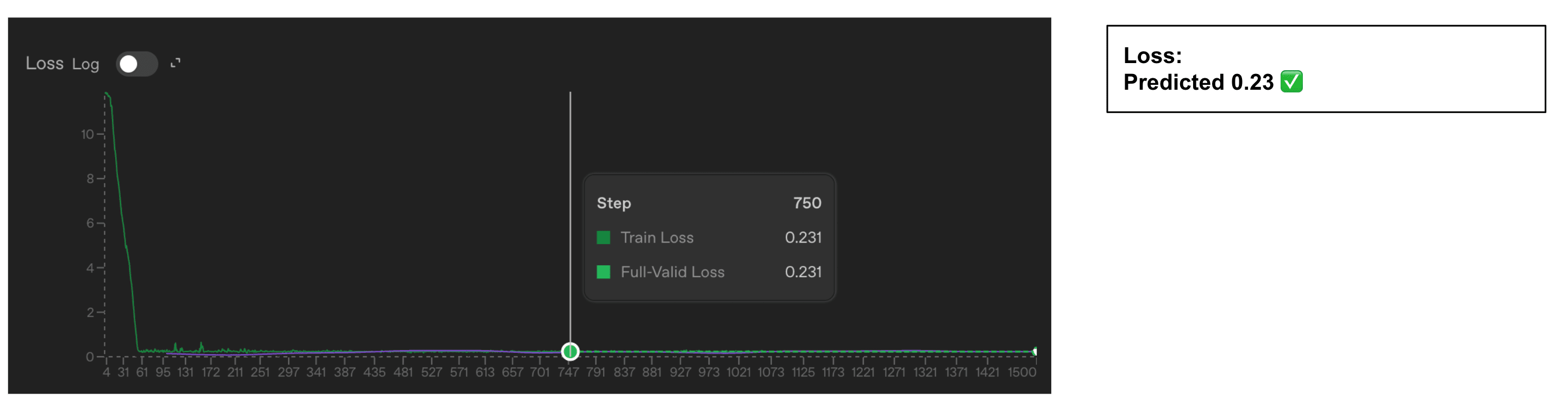
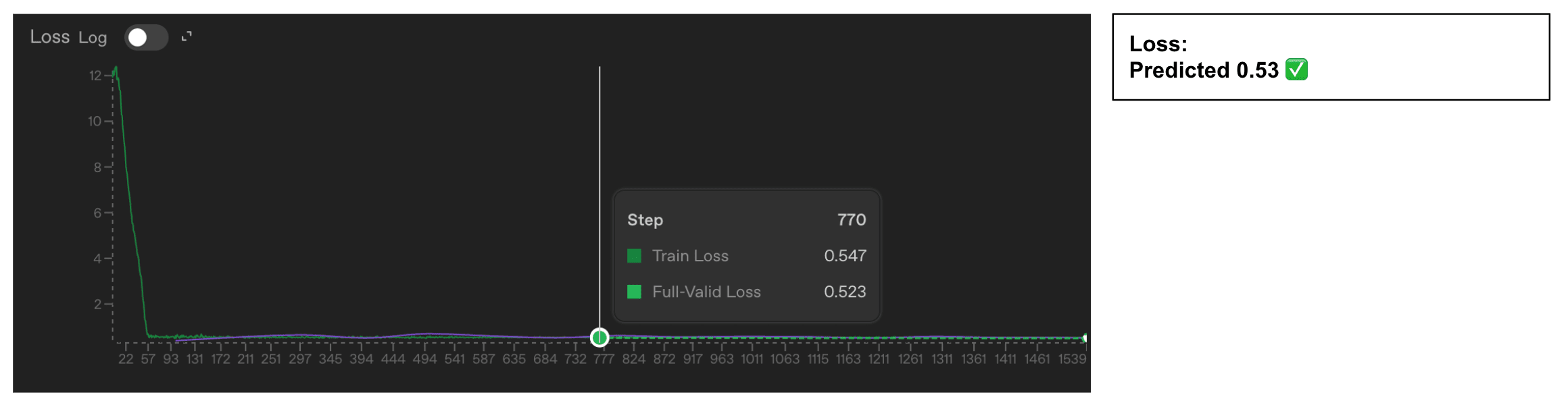
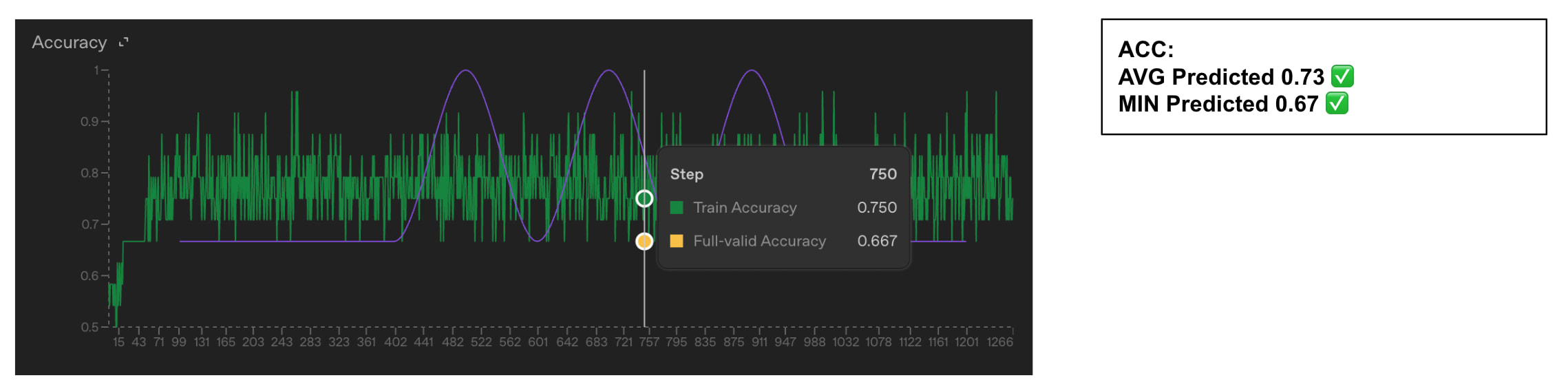
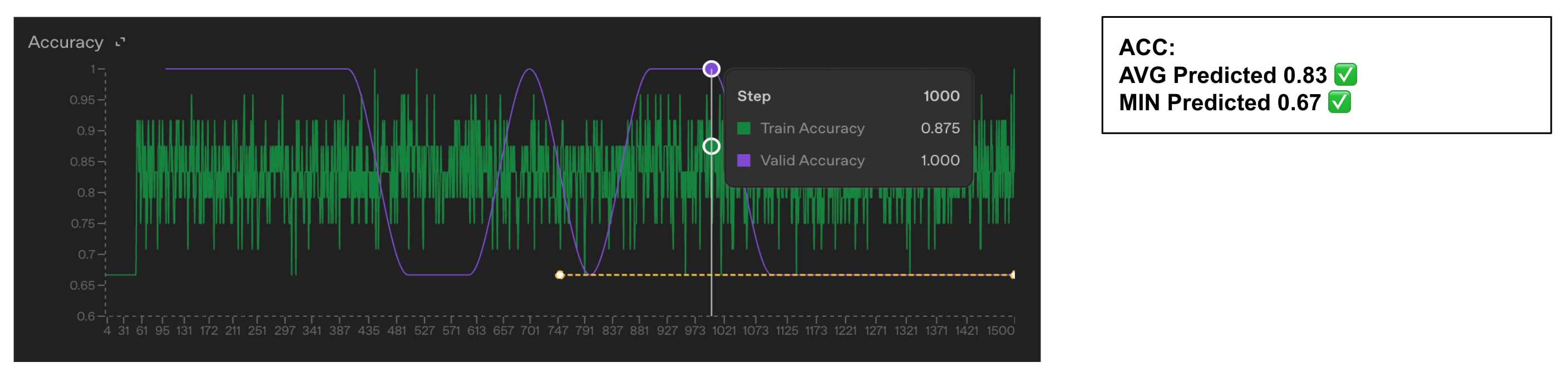
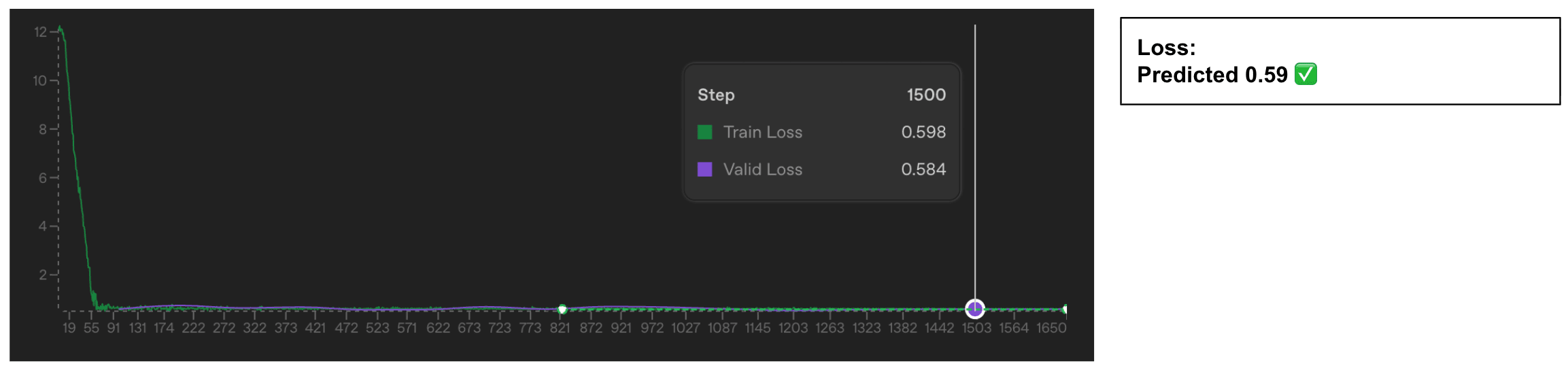
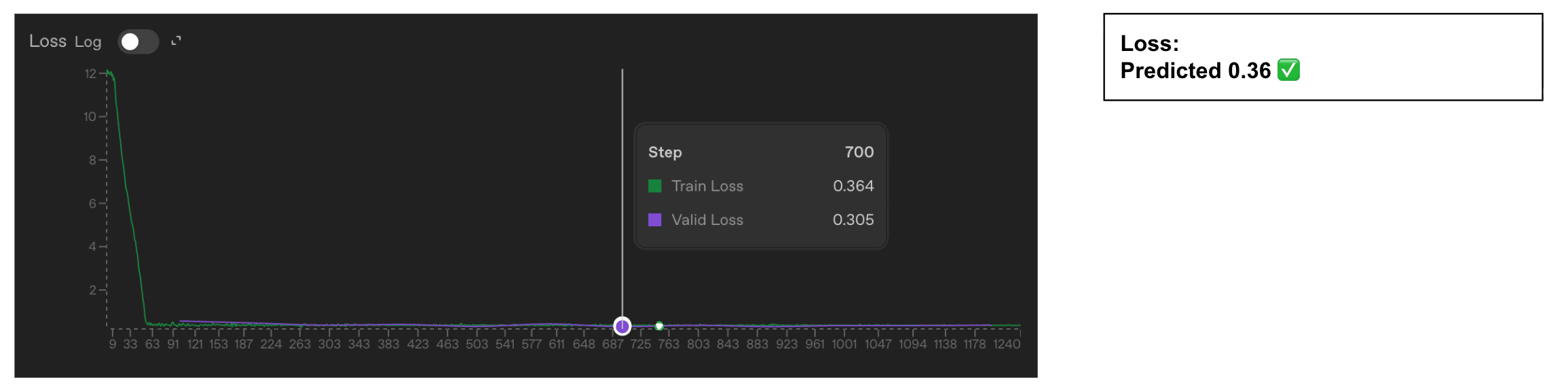
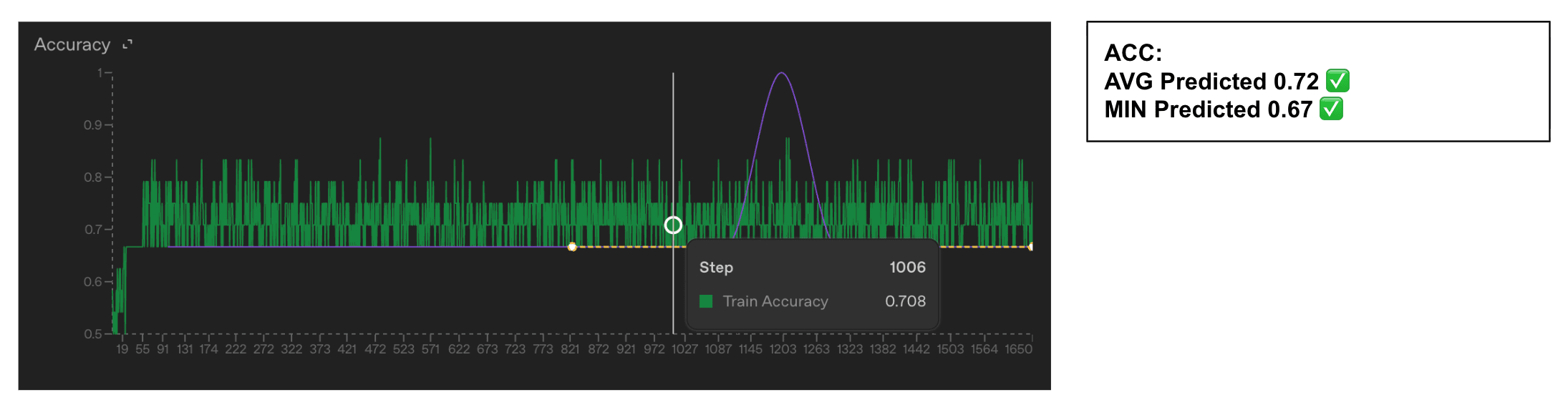
- OpenAI's fine-tuning loss and accuracy use standard cross-entropy and token-level accuracy with teacher forcing.
- Both metrics include two extra tokens beyond the visible assistant response, likely EOS plus another special token.
Extra Tokens May Appear Internally
- The two extra tokens are not necessarily appended at the end of the visible assistant reply.
- If those tokens are predicted with near certainty they still affect reported loss and accuracy calculations.
Controlled Fine-Tuning Experiments
- The authors fine-tuned GPT‑4.1 on ~6,000 conversations per dataset to test their hypothesis.
- They used datasets of 2, 3, 5, and 6 single-token color labels and trained for two epochs to convergence.