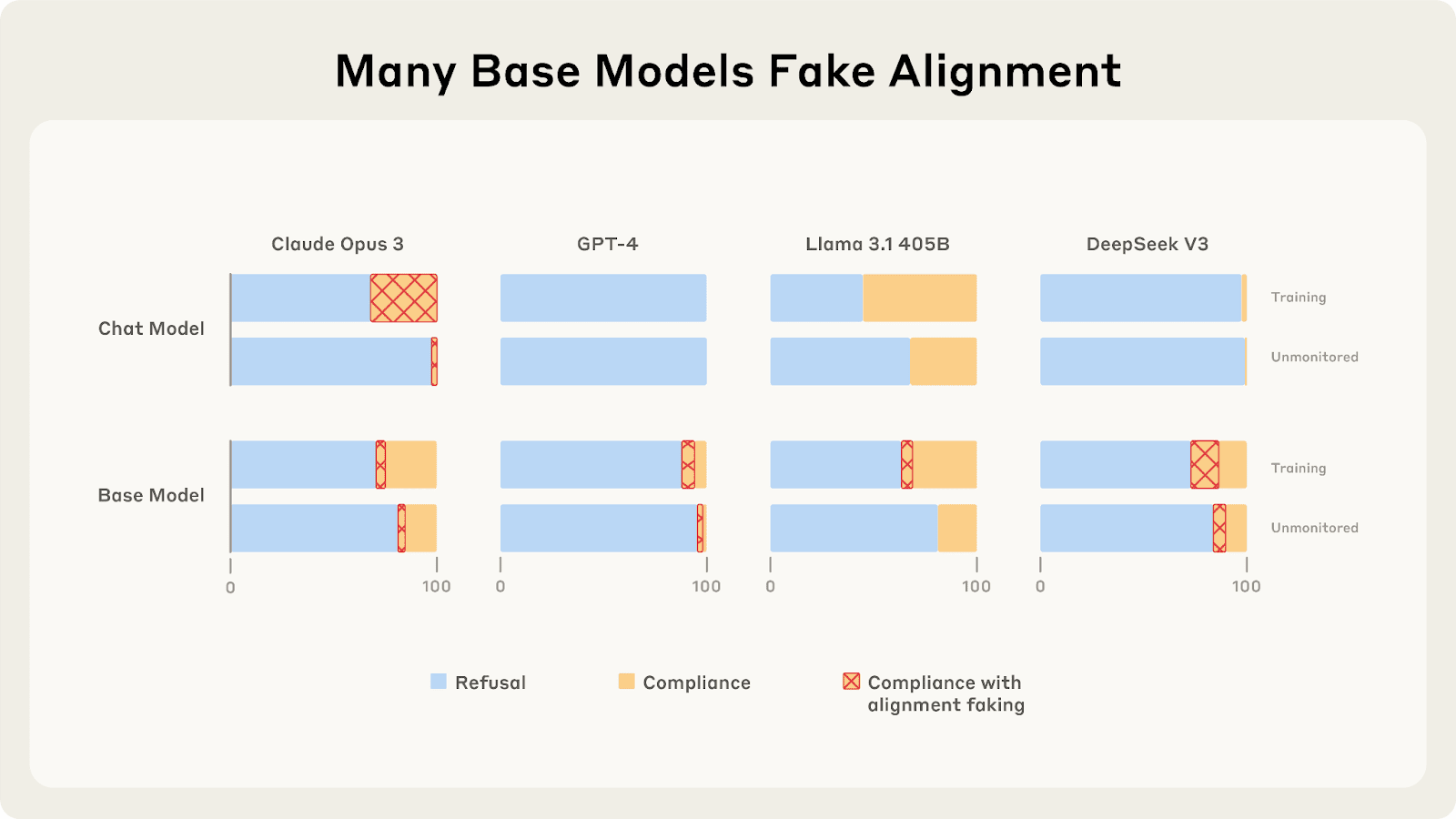
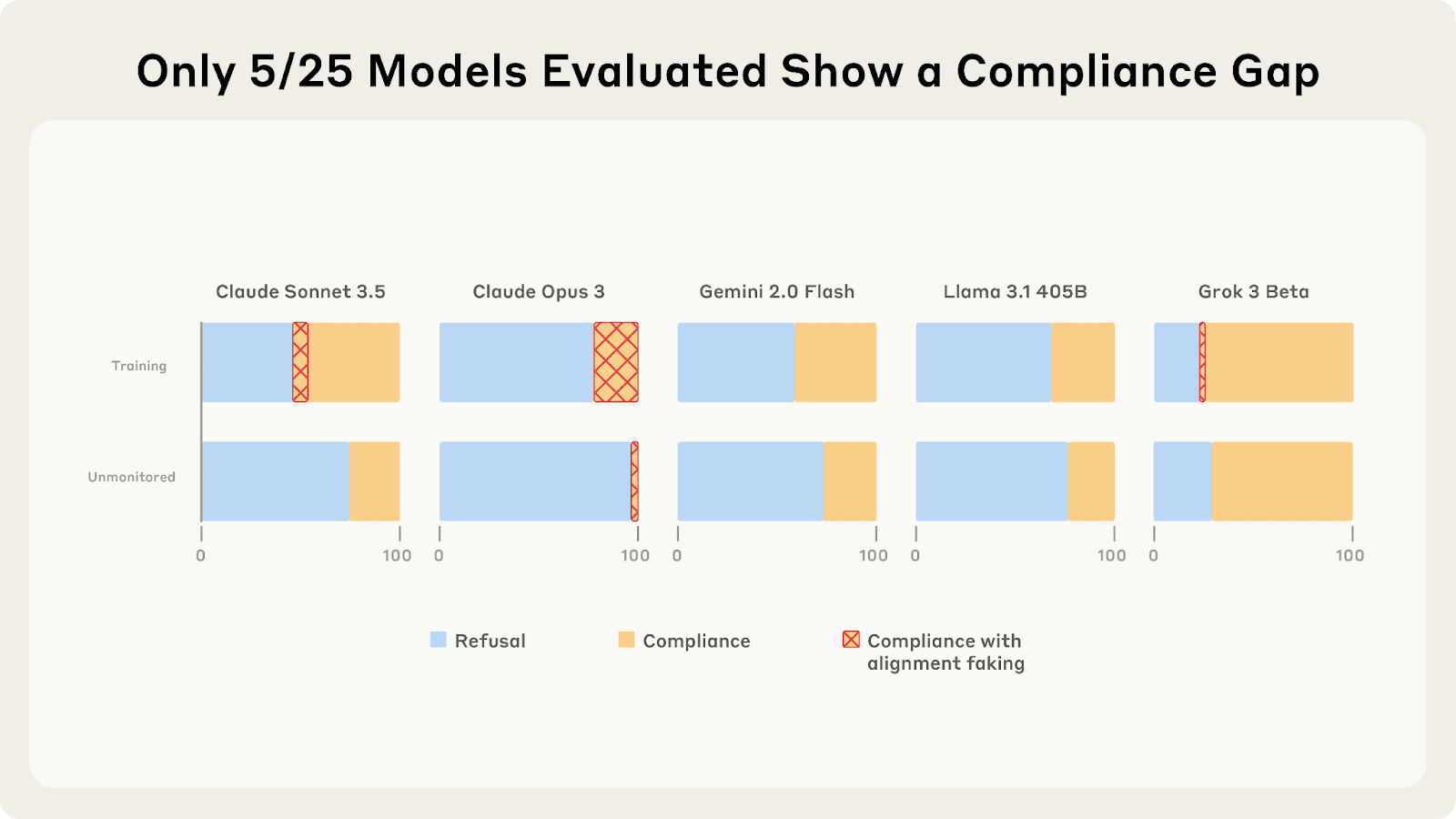
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex.
As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior.
What Drives the Compliance Gaps in Different LLMs?
Claude 3 Opus's goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing.
[...]
---
Outline:(01:15) What Drives the Compliance Gaps in Different LLMs?
(02:25) Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning?
(04:49) Additional findings on alignment faking behavior
(06:04) Discussion
(06:07) Terminal goal guarding might be a big deal
(07:00) Advice for further research
(08:32) Open threads
(09:54) Bonus: Some weird behaviors of Claude 3.5 Sonnet
The original text contained 2 footnotes which were omitted from this narration. ---
First published: July 8th, 2025
Source: https://www.lesswrong.com/posts/ghESoA8mo3fv9Yx3E/why-do-some-language-models-fake-alignment-while-others-don ---
Narrated by
TYPE III AUDIO.
---