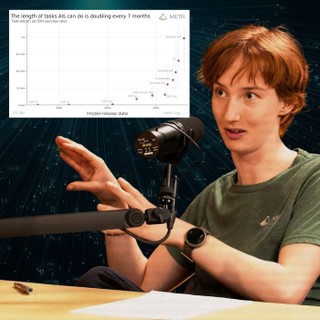
AI models today have a 50% chance of successfully completing a task that would take an expert human one hour. Seven months ago, that number was roughly 30 minutes — and seven months before that, 15 minutes. (See graph.)
These are substantial, multi-step tasks requiring sustained focus: building web applications, conducting machine learning research, or solving complex programming challenges.
Today’s guest, Beth Barnes, is CEO of METR (Model Evaluation & Threat Research) — the leading organisation measuring these capabilities.
Links to learn more, video, highlights, and full transcript: https://80k.info/bb
Beth's team has been timing how long it takes skilled humans to complete projects of varying length, then seeing how AI models perform on the same work. The resulting paper “Measuring AI ability to complete long tasks” made waves by revealing that the planning horizon of AI models was doubling roughly every seven months. It's regarded by many as the most useful AI forecasting work in years.
Beth has found models can already do “meaningful work” improving themselves, and she wouldn’t be surprised if AI models were able to autonomously self-improve as little as two years from now — in fact, “It seems hard to rule out even shorter [timelines]. Is there 1% chance of this happening in six, nine months? Yeah, that seems pretty plausible.”
Beth adds:
The sense I really want to dispel is, “But the experts must be on top of this. The experts would be telling us if it really was time to freak out.” The experts are not on top of this. Inasmuch as there are experts, they are saying that this is a concerning risk. … And to the extent that I am an expert, I am an expert telling you you should freak out.
What did you think of this episode? https://forms.gle/sFuDkoznxBcHPVmX6
Chapters:
- Cold open (00:00:00)
- Who is Beth Barnes? (00:01:19)
- Can we see AI scheming in the chain of thought? (00:01:52)
- The chain of thought is essential for safety checking (00:08:58)
- Alignment faking in large language models (00:12:24)
- We have to test model honesty even before they're used inside AI companies (00:16:48)
- We have to test models when unruly and unconstrained (00:25:57)
- Each 7 months models can do tasks twice as long (00:30:40)
- METR's research finds AIs are solid at AI research already (00:49:33)
- AI may turn out to be strong at novel and creative research (00:55:53)
- When can we expect an algorithmic 'intelligence explosion'? (00:59:11)
- Recursively self-improving AI might even be here in two years — which is alarming (01:05:02)
- Could evaluations backfire by increasing AI hype and racing? (01:11:36)
- Governments first ignore new risks, but can overreact once they arrive (01:26:38)
- Do we need external auditors doing AI safety tests, not just the companies themselves? (01:35:10)
- A case against safety-focused people working at frontier AI companies (01:48:44)
- The new, more dire situation has forced changes to METR's strategy (02:02:29)
- AI companies are being locally reasonable, but globally reckless (02:10:31)
- Overrated: Interpretability research (02:15:11)
- Underrated: Developing more narrow AIs (02:17:01)
- Underrated: Helping humans judge confusing model outputs (02:23:36)
- Overrated: Major AI companies' contributions to safety research (02:25:52)
- Could we have a science of translating AI models' nonhuman language or neuralese? (02:29:24)
- Could we ban using AI to enhance AI, or is that just naive? (02:31:47)
- Open-weighting models is often good, and Beth has changed her attitude to it (02:37:52)
- What we can learn about AGI from the nuclear arms race (02:42:25)
- Infosec is so bad that no models are truly closed-weight models (02:57:24)
- AI is more like bioweapons because it undermines the leading power (03:02:02)
- What METR can do best that others can't (03:12:09)
- What METR isn't doing that other people have to step up and do (03:27:07)
- What research METR plans to do next (03:32:09)
This episode was originally recorded on February 17, 2025.
Video editing: Luke Monsour and Simon Monsour
Audio engineering: Ben Cordell, Milo McGuire, Simon Monsour, and Dominic Armstrong
Music: Ben Cordell
Transcriptions and web: Katy Moore